38 KiB
第十二章 增强自我修复应用程序
Kubernetes 在计算和网络层上对应用程序进行抽象建模。这些抽象允许Kubernetes控制网络流量和容器的生命周期,因此如果应用程序的某些部分出现故障,它可以采取纠正措施。如果您的规范中有足够的细节,集群可以发现并修复临时问题,并保持应用程序在线。这些是自我修复的应用程序,可以在不需要人工指导的情况下渡过任何短暂的问题。在本章中,你将学习如何在你自己的应用程序中建模,使用容器探测来测试健康状况,并施加资源限制,这样应用程序就不会占用太多的计算量。
Kubernetes 的治疗能力是有限的,你也会在本章学到这些。我们将主要研究如何在没有手动管理的情况下保持应用程序的运行,但我们也将再次研究应用程序更新。更新是最有可能导致停机的原因,我们将看看Helm的一些其他功能,可以让你的应用在更新周期内保持健康。
12.1 使用 readiness 探测将流量路由到健康 Pods
Kubernetes 知道 Pod 容器是否正在运行,但它不知道容器内的应用程序是否健康。每个应用程序都有自己对“健康”的定义——对HTTP请求的响应可能是200 OK——Kubernetes提供了一种使用容器探测来测试健康状况的通用机制。Docker 镜像可以配置健康检查,但Kubernetes会忽略它们,而是使用自己的探测。探针在Pod spec 中定义,它们按照固定的时间表执行,测试应用程序的某些方面,并返回一个指示器,以判断应用程序是否仍然健康。
如果探测响应显示容器不健康,Kubernetes将采取行动,而所采取的行动取决于探测的类型。Readiness 探测在网络级执行操作,管理侦听网络请求的组件的路由。 如果 Pod 容器不健康,则将Pod从就绪状态中取出,并从服务的活动Pod列表中删除。图12.1显示了如何查找具有多个副本的部署,其中一个Pod不健康。
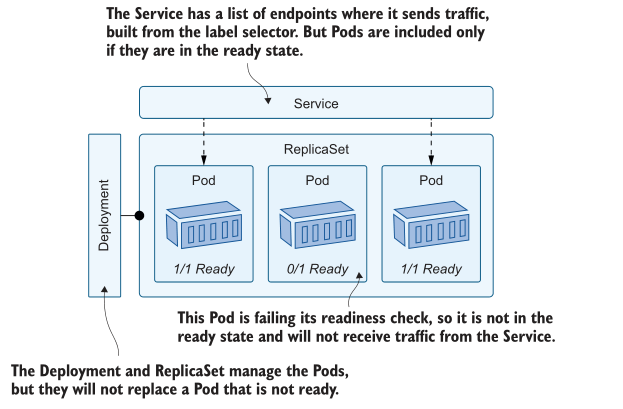
Readiness 就绪探测是管理临时负载问题的好方法。有些 pod 可能过载,对每个请求返回 503 状态代码。如果 readiness 就绪探测检查了200响应,而这些pod返回503,那么它们将从 Service 中删除,并停止接收请求。Kubernetes在探测器失败后继续运行探测器,所以如果过载的 Pod 在休息时有机会恢复,探测器将再次成功,Pod将重新加入 Service。
我们在本书中使用的随机数生成器有几个特性,我们可以使用它来了解它是如何工作的。API可以在一种模式下运行,即在特定数量的请求后失败,并且它具有一个HTTP端点,该端点返回它是正常状态还是处于失败状态。我们将在没有准备 readiness 探测的情况下运行它,以便了解问题。
现在试试吧,使用多个副本运行API,看看当应用程序在没有任何容器探测进行测试的情况下失败时会发生什么。
# 进入章节目录:
cd ch12
# 部署 random-number API:
kubectl apply -f numbers/
# 等待就绪:
kubectl wait --for=condition=ContainersReady pod -l app=numbers-api
# 确认 Pod 注册作为 Service endpoints:
kubectl get endpoints numbers-api
# 将 api url 保存到文本文件:
kubectl get svc numbers-api -o jsonpath='http://{.status.loadBalancer
.ingress[0].*}:8013' > api-url.txt
# 访问 API—返回之后, 应用会显示不正常:
curl "$(cat api-url.txt)/rng"
# 检查 health 端点:
curl "$(cat api-url.txt)/healthz"; curl "$(cat api-url.txt)/healthz"
# 确认 service 使用的 Pods:
kubectl get endpoints numbers-api
从本练习中您将看到,Service 将两个pod都保存在其端点列表中,尽管其中一个不健康,并且总是返回500错误响应。图12.2中的输出在请求之前和之后显示了端点列表中的两个IP地址,这导致一个实例变得不健康。

这是因为 Kubernetes 不知道其中一个pod是不健康的。Pod容器中的应用程序仍在运行,Kubernetes不知道有一个健康端点可以用来查看应用程序是否正常工作。你可以在Pod的容器 spec 中给它准备 readiness 探测的信息。清单12.1显示了API spec 的更新,其中包括健康检查。
清单 12.1 api-with-readiness.yaml, API 容器的 readiness 探测
spec: # 这是 Deployment 的 Pod spec
containers:
- image: kiamol/ch03-numbers-api
readinessProbe: # 探测在容器层面指定
httpGet:
path: /healthz # 这是一个 Get 路由
port: 80
periodSeconds: 5 # 探测每隔 5 秒钟触发
Kubernetes 支持不同类型的容器探测。这一个使用HTTP GET操作,这是完美的web应用程序和api。探测器告诉Kubernetes每5秒测试一次/healthz端点;如果响应的HTTP状态码在200到399之间,则探测成功;如果返回任何其他状态代码,它将失败。随机数API在不健康时返回500代码,因此我们可以看到准备就绪探测的工作。
现在试试吧,部署更新后的 spec ,并验证包含失败应用程序的Pod已从 Service 中删除。
# 部署清单 12.1 更新的 spec:
kubectl apply -f numbers/update/api-with-readiness.yaml
# 等待替换的 Pods 就绪:
kubectl wait --for=condition=ContainersReady pod -l app=numbers-api,version=v2
# 检查 endpoints:
kubectl get endpoints numbers-api
# 触发一个应用容器变成不健康状态:
curl "$(cat api-url.txt)/rng"
# 等待 readiness 探测生效:
sleep 10
# 再次检查 endpoints:
kubectl get endpoints numbers-api
如图12.3中的输出所示,readiness 探测检测到其中一个pod不健康,因为对HTTP请求的响应返回500。Pod的IP地址从服务端点列表中删除,因此它将不再接收任何流量。
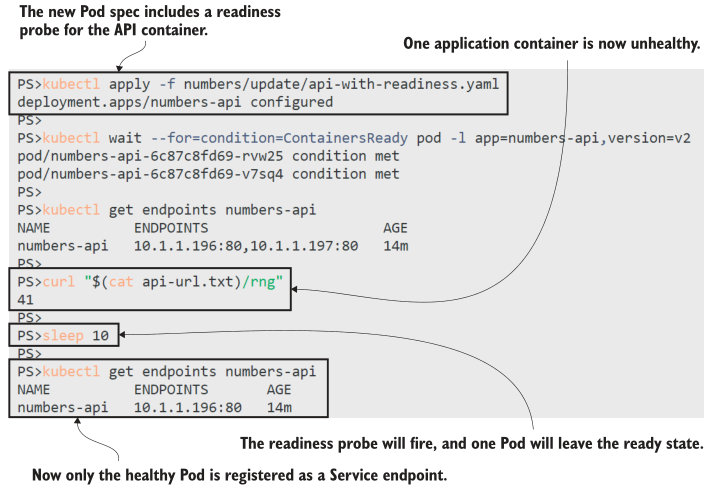
这个应用程序也是一个很好的例子,说明准备 readiness 探测本身是多么危险。随机数API中的逻辑意味着一旦失败,它将始终失败,因此不健康的Pod将被排除在服务之外,应用程序将以低于预期的容量运行。当探测失败时,部署不会替换离开就绪状态的pod,因此我们留下两个正在运行的pod,但只有一个接收流量。如果另一个Pod也失败了,情况会更糟。
现在试试吧,服务列表中只有一个Pod。你会发出一个请求,Pod也会变得不健康,所以两个Pod都会从服务中删除。
# 检查 Service endpoints:
kubectl get endpoints numbers-api
# 访问 API, 触发应用都变成不健康状态:
curl "$(cat api-url.txt)/rng"
# 等待 readiness 探测触发:
sleep 10
# 再次检查 endpoints:
kubectl get endpoints numbers-api
# 检查 Pod status:
kubectl get pods -l app=numbers-api
# 我们可以重置 API... 但是没有 Pods 可以接受请求,所以将会失败:
curl "$(cat api-url.txt)/reset"
现在我们有了一个解决方案——两个pod readiness 就绪探测都失败了,Kubernetes已经从服务端点列表中删除了它们。这样服务就没有端点了,所以应用程序处于离线状态,如图12.4所示。现在的情况是,任何试图使用API的客户端都会得到一个连接失败,而不是一个HTTP错误状态代码,对于试图使用特殊管理URL重置应用程序的管理员来说也是如此。
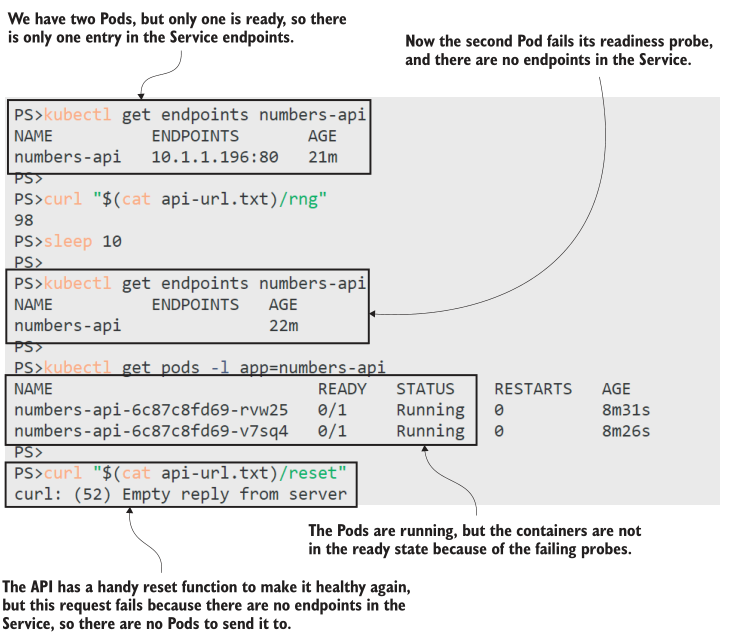
如果您认为“这不是一个自我修复应用程序”,那么您完全正确,但请记住,应用程序无论如何都处于失败状态。没有 readiness 就绪探测,应用程序仍然不能工作,但有了 readiness 就绪探测,它就不会受到攻击请求,直到它恢复并能够处理它们。您需要了解应用程序的失败模式,以了解当探测失败时会发生什么,以及应用程序是否可能自行恢复。
随机数API再也不会恢复正常,但我们可以通过重新启动Pod来修复失败状态。如果你在容器 spec 中包含另一个健康检查:一个 liveness 探测,Kubernetes将为你做这件事。
12.2 通过 liveness 探测重启不健康的 Pods
Liveness 探针使用与 readiness 探针相同的健康检查机制——在Pod spec 中测试配置可能是相同的——但失败探针的操作是不同的。liveness 探测在计算级采取行动,如果pod变得不健康,将重新启动pod。重启是当Kubernetes用一个新的Pod容器替换Pod容器时;Pods 本身没有被替换;它继续在相同的节点上运行,但是使用了一个新的容器。
清单 12.2 显示了用于随机数API的 liveness 探测。这个探测使用相同的HTTP GET操作来运行探测,但是它有一些额外的配置。
重新启动 Pod 比从 Service 中删除它更具侵入性,并且额外的设置有助于确保仅在我们真正需要它时才发生。
清单 12.2 api-with-readiness-and-liveness.yaml, 添加 liveness probe
livenessProbe:
httpGet: # HTTP GET 可以使用在 liveness 和 readiness 探测 - 他们使用相同的配置
path: /healthz
port: 80
periodSeconds: 10
initialDelaySeconds: 10 # 在第一次探测前等待 10 秒
failureThreshold: 2 # 在采取进一步行动前允许两次探测失败
这是对Pod spec 的更改,因此应用更新将创建新的替换Pod,开始时健康。这一次,当Pod在应用程序失败后变得不健康时,由于 readiness 就绪探测,它将从 service 中删除。由于 liveness 探针,它将重新启动,然后Pod将被添加回 Service 中。
现在试试吧,更新API,并验证 liveness 状态检查和 readiness 状态检查相结合是否能保持应用程序正常运行。
# 部署清单 12.2 的更新:
kubectl apply -f numbers/update/api-with-readiness-and-liveness.yaml
# 等待新 pods 就绪:
kubectl wait --for=condition=ContainersReady pod -l app=numbers-api,version=v3
# 检查 Pod status:
kubectl get pods -l app=numbers-api -o wide
# 检查 Servivce endpoints:
kubectl get endpoints numbers-api # two
# 使其中一个 Pod 变成不健康:
curl "$(cat api-url.txt)/rng"
# 等待探测触发, 然后再次检查 pods:
sleep 20
kubectl get pods -l app=numbers-api
在本练习中,您将看到 liveness 探测的运行,在应用程序失败时重新启动Pod。重新启动是一个新的Pod容器,但是Pod环境是一样的——它有相同的IP地址,如果容器在Pod中挂载了一个EmptyDir卷,它就可以访问由前一个容器写入的文件。在图12.5中可以看到,两个pod在重新启动后都在运行并准备就绪,因此Kubernetes修复了故障并修复了应用程序。

如果应用程序一直失败而没有健康的表现,重新启动并不是一个永久性的解决方案,因为Kubernetes不会无限期地重新启动一个失败的Pod。对于瞬态问题,它工作得很好,只要应用程序可以在替换容器中成功重新启动。探测对于在升级期间保持应用程序健康也很有用,因为只有当新的pod进入就绪状态时,才会进行铺开,因此如果 readiness 就绪探测失败,将暂停铺开。
我们将通过待办事项列表应用程序来展示这一点,其中的 spec 包括对web应用程序Pod和数据库的 liveness和 readiness 检查。web探针使用我们已经看到的相同的HTTP GET操作,但是数据库没有我们可以使用的HTTP端点。相反,该 spec 使用了Kubernetes支持的其他类型的探测动作——TCP套接字动作,用于检查端口是否打开并侦听传入的流量,以及exec动作,用于在容器内运行命令。清单12.3显示了探针的设置。
清单 12.3 todo-db.yaml, 使用 TCP 和 command 探针
spec:
containers:
- image: postgres:11.6-alpine
readinessProbe:
tcpSocket: # readiness 探测测试数据库监听端口
port: 5432
periodSeconds: 5
livenessProbe: # liveness 探测运行一个 Postgres 工具确认数据库在运行
exec:
command: ["pg_isready", "-h", "localhost"]
periodSeconds: 10
initialDelaySeconds: 10
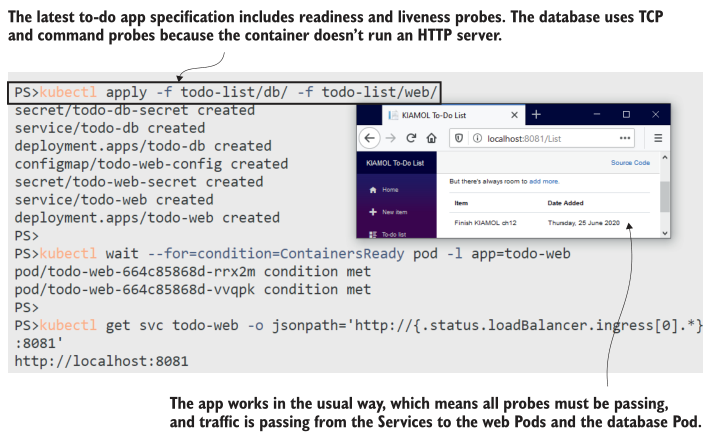
当你部署这段代码时,你会看到应用程序的工作方式和往常一样,但现在它受到了保护,防止了web和数据库组件中的瞬时故障。
现在试试吧,使用新的自修复 spec 运行待办事项列表应用程序。
# 部署 web and database:
kubectl apply -f todo-list/db/ -f todo-list/web/
# 等待应用 ready:
kubectl wait --for=condition=ContainersReady pod -l app=todo-web
# 获取 service url:
kubectl get svc todo-web -o
jsonpath='http://{.status.loadBalancer.ingress[0].*}:8081'
# 访问并添加一个数据项
这里没有什么新内容,如图12.6中的输出所示。但是数据库探测意味着Postgres在数据库准备好之前不会收到任何流量,如果Postgres服务器失败,则数据库Pod将重新启动,使用Pod中EmptyDir卷中的相同数据文件进行替换。
容器探测还可以在更新出错时保持应用程序运行。待办事项应用程序有一个新的数据库 spec,它升级了Postgres的版本,但它也覆盖了容器命令,所以它会休眠而不是启动Postgres。这是一个典型的调试遗留错误:有人想用正确的配置启动Pod,但没有运行应用程序,这样他们就可以在容器中运行shell来检查环境,但他们没有恢复他们的更改。如果Pod没有任何探测,更新将成功并关闭应用程序。sleep命令保持Pod容器运行,但没有数据库服务器供网站使用。探测会阻止这种情况发生,并保持应用程序可用。
现在试试吧,部署坏的更新,并验证新Pod中失败的探测阻止了原始Pod被删除。
# 部署更新:
kubectl apply -f todo-list/db/update/todo-db-bad-command.yaml
# 监控 Pod 状态变更:
kubectl get pods -l app=todo-db --watch
# 刷新应用确认应用还正常工作
# ctrl-c or cmd-c to exit the Kubectl watch
可以在图12.7中看到我的输出。创建了替换数据库Pod,但它永远不会进入就绪状态,因为就绪探测检查端口5342是否有进程在监听,但没有。Pod也会不断重新启动,因为 liveness 探测会运行一个命令来检查Postgres是否准备好接收客户端连接。虽然新的Pod不断出现故障,但旧的Pod仍在运行,应用程序也在继续工作。
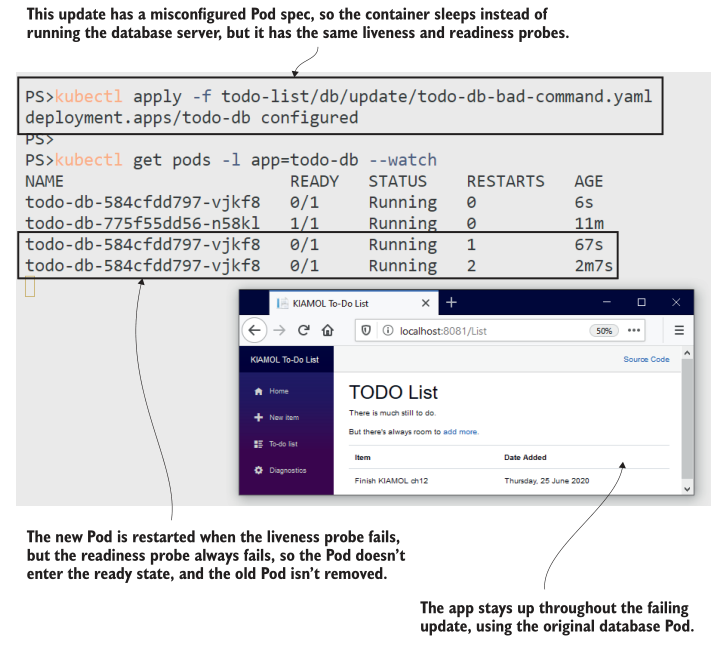
如果你让这个应用程序再运行五分钟左右,然后再次检查Pod状态,你会看到新的Pod进入CrashLoopBackOff状态。这就是Kubernetes如何保护集群不浪费计算资源在不断失败的应用程序上:它在Pod重新启动之间增加了一个时间延迟,并且这个延迟随着每次重新启动而增加。如果你在CrashLoopBackOff中看到Pod,这通常意味着应用程序无法修复。
待办事项应用程序现在的情况与我们在第9章中首次看到的rollout失败相同。Deployment正在管理两个ReplicaSets,它的目标是在新的ReplicaSets达到容量后,将旧的ReplicaSets缩小到零。但是新的ReplicaSet 永远不会达到容量,因为新Pod中的探针不断失效。部署就这样,希望它最终能完成部署。Kubernetes没有自动回滚选项,但Helm有,您可以扩展Helm Chart 以支持健康升级。
12.3 使用 Helm 安全地部署升级
有 Helm 的话帮助就很大了。您已经在第10章学习了基本知识,不需要深入了解模板函数和依赖管理,就可以很好地利用Helm进行安全的应用程序升级。Helm支持原子安装和升级,如果失败会自动回滚,而且它还有一个部署生命周期,可以在安装前后运行验证作业。
本章的源文件夹有多个用于待办事项应用程序的Helm Chart,它们代表不同的版本(通常情况下,每个版本都有一个单独的Helm Chart)。版本1 chart使用我们在第12.2节中使用的相同的 liveness和 readiness 检查来部署应用程序;唯一的区别是数据库使用PersistentVolumeClaim,因此数据在升级之间被保留。我们将从清理之前的练习和安装Helm版本开始。
现在试试吧,使用相同的Pod spec 运行待办事项应用程序,但使用 Helm chart 进行部署。
# 删除章节已存在的应用:
kubectl delete all -l kiamol=ch12
# 安装 Helm release:
helm install --atomic todo-list todo-list/helm/v1/todo-list/
# 访问应用,添加新的数据项
该应用的 Version 1 现在正在Helm上运行,除了 chart 在模板文件夹中包含一个名为NOTES.txt的文件外,这里没有什么新内容,该文件显示了安装后看到的有用文本。我的输出如图12.8所示。我没有附上应用程序的截图,所以你只需要相信我的话,我浏览了并添加了一个条目,上面写着“完成第12章”。
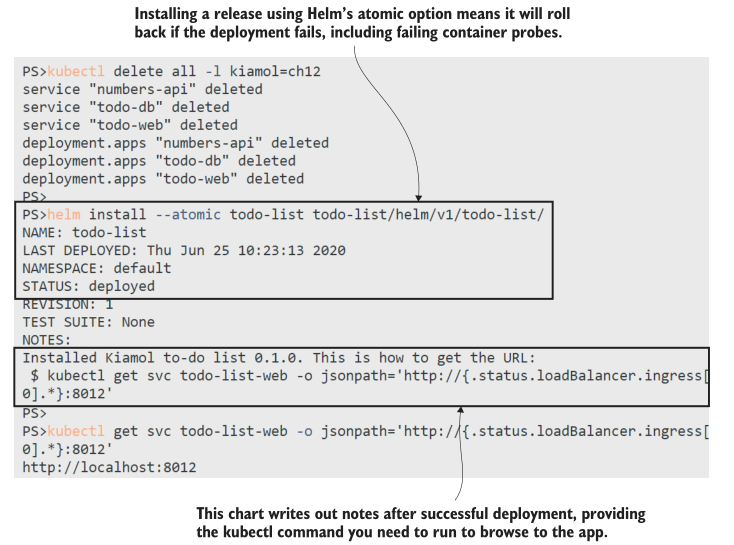
Helm chart 的 Version 2 尝试了我们在第12.2节中看到的相同的数据库镜像升级,完成了Postgres容器命令中的错误配置。当您使用 Helm 部署它时,同样的事情在底层发生:Kubernetes更新部署,这添加了一个新的ReplicaSet,并且ReplicaSet永远不会达到容量,因为Pod readiness 探测失败。但是Helm会检查 rollout 的状态,如果在特定的时间内没有成功,它会自动回滚。
现在试试吧, 使用Helm升级待办事项应用程序发布。升级失败是因为 Pod spec 配置错误,Helm 将其回滚。
# 列出当前 Pod 状态以及容器镜像信息:
kubectl get pods -l app=todo-list-db -o=custom-columns=NAME:.metadata.name,STATUS:.status.phase,IMAGE:.spec.containers[0].image
# 通过 helm 升级 release—将会失败:
helm upgrade --atomic --timeout 30s todo-list todo-list/helm/v2/todo-list/
# 再次列出 Pods:
kubectl get pods -l app=todo-list-db -o=custom-columns=NAME:.metadata.name,STATUS:.status.phase,IMAGE:.spec.containers[0].image
# 访问应用,刷新列表
如果在该练习中检查 Pod 列表几次,就会看到发生了回滚,如图12.9所示。起初,只有一个运行Postgres 11.6的Pod,然后加入了一个运行11.8的新Pod,但那是一个容器探测失败的Pod。Pod在Helm超时时间内没有准备好,因此升级回滚,新的 Pod 被移除;它不会像kubectl更新那样不断重新启动并命中CrashLoopBackOff。
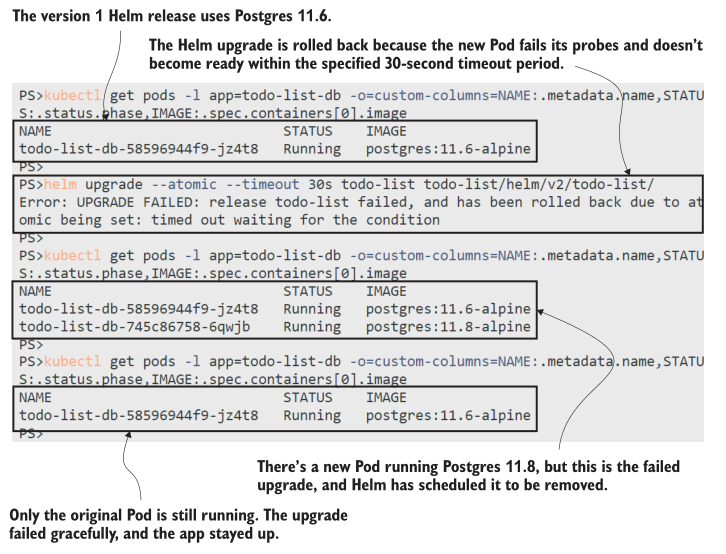
在升级到版本 2 失败期间,待办事项应用程序一直在线,没有中断或减少容量。下一个版本通过删除Pod spec 中的坏容器命令修复了升级,它还为 Kubernetes Job添加了一个额外的模板,您可以使用 Helm 作为部署测试运行。测试按需运行,而不是作为安装的一部分,因此它们非常适合烟雾测试—您可以运行这些自动化测试套件来确认成功的发行版正在正确运行。清单 12.4 显示了待办事项数据库的测试。
清单 12.4 todo-db-test-job.yaml, Kubernetes Job 作为 Helm 测试运行
apiVersion: batch/v1
kind: Job # 这个是标准的 Job spec
metadata:
# metadata 包括 name 和 labels
annotations:
"helm.sh/hook": test # 告诉Helm Job可以在发布的测试套件中运行
spec:
completions: 1
backoffLimit: 0 # 作业应该运行一次,而不是重试。
template:
spec: # 容器 spec 运行一个 sql 查询
containers:
- image: postgres:11.8-alpine
command: ["psql", "-c", "SELECT COUNT(*) FROM \"public\".\"ToDos\""]
我们在第 8 章中用到了 Jobs,helm 很好地利用了他们。Job specs 包括期望运行多少次才能成功完成,Helm 使用该期望来评估测试是否成功。版本 3 升级应该会成功,当它完成时,您可以运行测试 Job,它将运行一条 SQL 语句来确认待办事项数据库是可访问的。
现在试试吧,升级到版本 3 chart,修复Postgres更新。然后用 Helm 运行测试,并检查 Job Pod 的日志。
# 执行升级:
helm upgrade --atomic --timeout 30s todo-list todo-list/helm/v3/todo-list/
# 列出数据库 Pods 和镜像:
kubectl get pods -l app=todo-list-db -o=custom-columns=NAME:.metadata.name,STATUS:.status.phase,IMAGE:.spec.containers[0].image,IP:.status.podIPs[].ip
# 检查数据库 Service 端点:
kubectl get endpoints todo-list-db
# 现在使用 helm 运行 test job:
helm test todo-list
# 检查输出:
kubectl logs -l job-name=todo-list-db-test
我在图12.10中截取了我的输出,但是细节都在那里——升级成功了,但是没有作为升级命令一部分的测试。数据库现在使用升级版的Postgres,当测试运行时,Job连接到数据库并确认数据仍然存在。
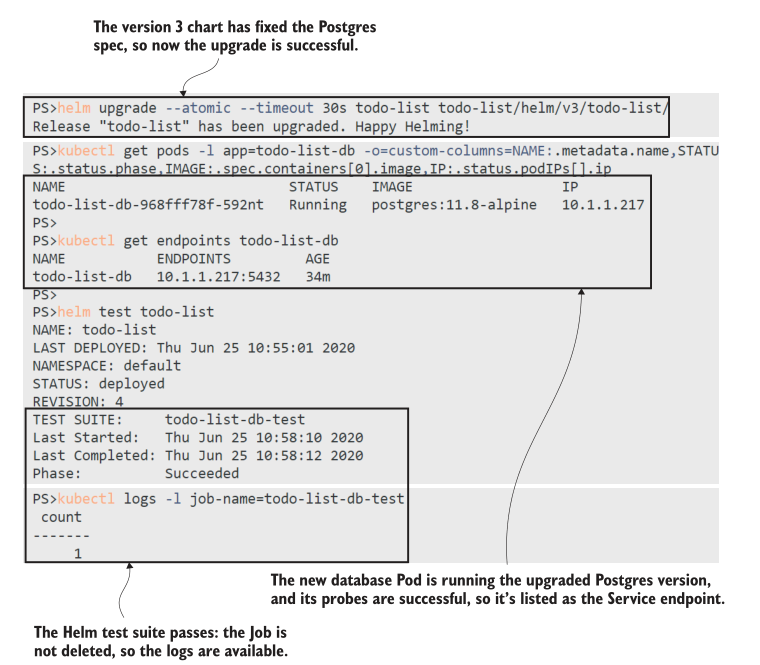
Helm 为你管理 Jobs。它不会清理已完成的作业,因此如果需要,您可以检查Pod状态和日志,但是当您重复测试命令时,它会替换它们,因此您可以随时重新运行测试套件。job还有另一个用途,它有助于确保升级是安全的,在升级之前运行它们,这样您就可以检查当前版本是否处于可以升级的有效状态。
如果你的应用程序支持多个版本,但只支持增量升级,那么这个功能就特别有用,所以版本1.1需要先升级到版本1.2,然后才能升级到版本2。这样做的逻辑可能涉及到查询不同服务的API版本或数据库的模式版本,Helm 可以在一个Job中运行,该Job可以访问所有其他Kubernetes对象,这些对象与应用程序Pods共享相同的ConfigMaps和Secrets。清单12.5显示了版本4中的待办事项Helm chart 的升级前测试。
清单 12.5 todo-db-check-job.yaml, 在 helm 升级前运行的 job
apiVersion: batch/v1
kind: Job # 标准的 job spec
metadata:
# metadata has name and labels
annotations:
"helm.sh/hook": pre-upgrade # 它在升级之前运行,并告诉Helm创建的顺序
"helm.sh/hook-weight": "10"
spec:
template:
spec:
restartPolicy: Never
containers:
- image: postgres:11.8-alpine
# env includes secrets
command: ["/scripts/check-postgres-version.sh"]
volumeMounts:
- name: scripts
mountPath: "/scripts"
升级前检查有两个模板:一个是 Job spec,另一个是 ConfigMap,其中包含要在 Job 中运行的脚本。您可以使用注释来控制 Helm 生命周期中需要运行Job的位置,并且此Job仅在升级时运行,而不是作为新安装的一部分运行。权重注释确保在Job之前创建ConfigMap。生命周期和权重让您可以在Helm中建模复杂的验证步骤,但是这个很简单——它升级数据库镜像,但前提是该版本目前运行的是11.6版本。
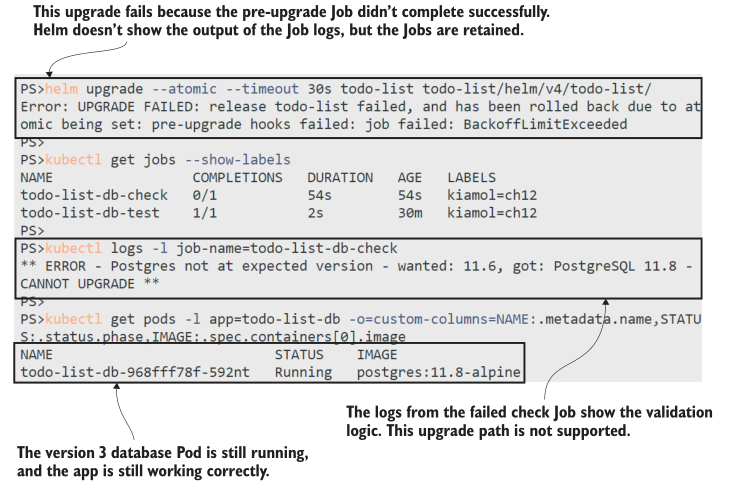
现在试试吧,从版本3升级到版本4无效,因为版本3已经升级了Postgres版本。运行升级以验证它没有被部署。
# 运行升级到 version 4— 将会失败:
helm upgrade --atomic --timeout 30s todo-list todo-list/helm/v4/todo-list/
# 列出 Jobs:
kubectl get jobs --show-labels
# 输出 pre-upgrade job 的日志输出:
kubectl logs -l job-name=todo-list-db-check
# 确认 database pod 并没有变化:
kubectl get pods -l app=todo-list-db -o=custom-columns=NAME:.metadata.name,STATUS:.status.phase,IMAGE:.spec.containers[0].image
在本练习中,您将看到Helm有效地阻止了升级,因为升级前钩子运行并且Job失败。这些都记录在发行版的历史记录中,这将显示最新的升级失败,并且发行版已回滚到最后一个良好的修订。我的输出如图12.11所示,在整个更新过程中,应用程序仍然可用。
了解Helm在保持应用程序健康方面所带来的好处是有益的,因为升级前验证和自动回滚也有助于保持应用程序升级的自我修复。Helm不是这样做的先决条件,但如果您不使用Helm,则应该考虑在部署管道中使用kubectl实现这些特性。在本章中,我们还将介绍应用程序运行状况的另一部分——管理Pod容器可用的计算资源。
12.4 通过 resource limits 保护应用和节点
容器是应用程序进程的虚拟环境。Kubernetes构建了该环境,并且您知道Kubernetes创建了容器文件系统并设置了网络。容器环境还包括内存和CPU,这些也可以由Kubernetes管理,但默认情况下,它们不是。这意味着Pod容器可以访问它们正在运行的节点上的所有内存和CPU,这是不好的,原因有两个:应用程序可能会耗尽内存并崩溃,或者它们会耗尽节点的资源,从而使其他应用程序无法运行。
您可以在 Pod spec 中限制容器的可用资源,这些限制就像容器探针一样——如果没有它们,您真的不应该进入生产环境。有内存泄漏的应用程序可以很快地破坏您的集群,导致 CPU 峰值对入侵者来说是一个很好的、容易的攻击向量。在本节中,您将学习如何配置您的 Pods 来防止这种情况,我们将从一个内存需求很大的新应用程序开始。
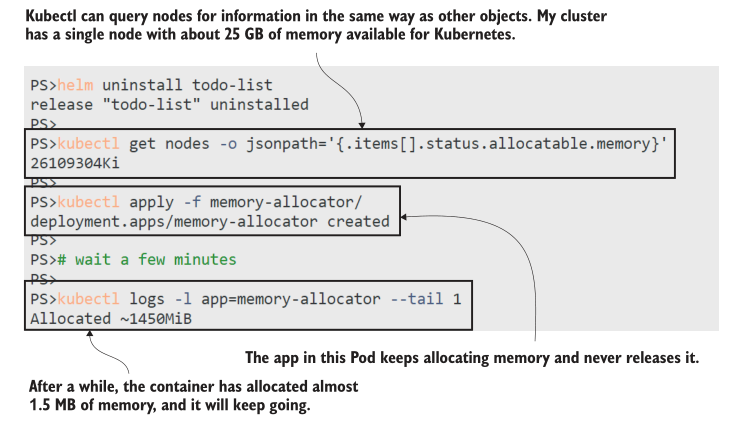
现在试试吧,从上一个练习中清除,并运行新的应用程序—除了分配内存和记录已分配的内存量外,它什么也不做。这个Pod运行没有任何容器限制。
# 删除 helm release 释放资源:
helm uninstall todo-list
# 打印你的节点拥有多少内存可分配:
kubectl get nodes -o jsonpath='{.items[].status.allocatable.memory}'
# 部署内存分配应用程序:
kubectl apply -f memory-allocator/
# 等待几分钟,然后查看它分配了多少内存:
kubectl logs -l app=memory-allocator --tail 1
内存分配器应用程序每5秒就会获取大约 10mb 的内存,并且它将一直持续下去,直到用完实验室集群中的所有内存。您可以从图12.12中的输出中看到,我的Docker Desktop节点可以访问大约25 GB的内存,而在我截屏时,allocator应用程序已经占用了近1.5 GB的内存。
只要应用程序在运行,它就会继续分配内存,所以我们需要在我的机器死机之前快速启动,以免我失去对这一章的编辑。清单12.6显示了一个更新的Pod spec,其中包括资源限制,将应用程序的内存限制在50 MB。
清单 12.6 memory-allocator-with-limit.yaml, 添加 memory limits 到容器
spec: # Deployment 中的 Pod spec
containers:
- image: kiamol/ch12-memory-allocator
resources:
limits: # resources limits 限制了容器的计算能力;这将 RAM 限制在50 MB。
memory: 50Mi
资源是在容器级别指定的,但这是一个新的Pod spec,所以当您部署更新时,您将得到一个新的Pod。替换开始时没有分配内存,然后每隔5秒重新分配10mb。然而,现在它将达到50mb的限制,Kubernetes将采取行动。
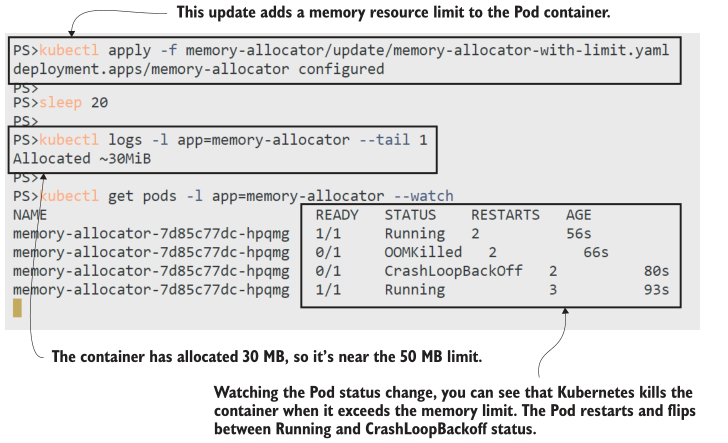
现在试试吧,使用清单12.6中定义的资源限制将更新部署到内存分配器应用程序。您应该看到Pod已重新启动,但前提是您的Linux主机在没有启用交换内存的情况下运行。K3s没有这个设置(除非你使用Vagrant VM设置),所以你不会看到与Docker Desktop或云Kubernetes服务相同的结果。
# 应用更新:
kubectl apply -f memory-allocator/update/memory-allocator-with-limit.yaml
# 等待应用程序分配内存块:
sleep 20
# 打印应用日志:
kubectl logs -l app=memory-allocator --tail 1
# 查看 Pod 状态:
kubectl get pods -l app=memory-allocator --watch
在本练习中,您将看到Kubernetes强制执行内存限制:当应用程序试图分配超过50mb的内存时,容器将被替换,您可以看到Pod进入OOMKilled状态。超过限制会导致Pod重新启动,因此这与失败的 liveiness探测有相同的缺点——如果替换容器一直失败,随着Kubernetes应用CrashLoopBackOff, Pod重新启动将花费越来越长的时间,如图12.13所示。
应用资源约束的困难之处在于确定限制应该是什么。您需要考虑一些性能测试,以了解您的应用程序可以管理什么—要注意,如果某些应用程序平台看到大量可用内存,它们会占用超过所需的内存。您应该宽宏大量地发布初始版本,然后随着您从监视中获得更多反馈,逐渐降低限制。
您还可以以另一种方式应用资源限制——为命名空间指定最大配额。这种方法对于使用命名空间为不同团队或环境划分集群的共享集群特别有用;您可以强制限制命名空间可以使用的资源总量。清单12.7显示了ResourceQuota对象的 spec,它将名为kiamol-ch12-memory 的命名空间中的可用内存总量限制在150 MB。
清单 12.7 02-memory-quota.yaml, 为命名空间设置内存配额
apiVersion: v1
kind: ResourceQuota # ResourceQuota 生效在指定的命名空间
metadata:
name: memory-quota
namespace: kiamol-ch12-memory
spec:
hard: # 配额包括 CPU 和内存
limits.memory: 150Mi
容器限制是反应性的,因此当内存限制超过时 pod 将重新启动。因为资源配额是主动的,所以如果 pod 指定的限制超过了配额中的可用容量,则不会创建pod。如果有配额,那么每个Pod spec 都需要包含一个资源部分,这样Kubernetes就可以将规范需要的资源与命名空间中当前可用的资源进行比较。下面是内存分配器 spec 的更新版本,其中Pod指定了一个大于配额的限制。
现在试试吧,在应用了资源配额的命名空间中部署内存分配器的新版本。
# 删除之前的应用:
kubectl delete deploy memory-allocator
# 部署 namespace, quota, 以及新的 Deployment:
kubectl apply -f memory-allocator/namespace-with-quota/
# 打印 ReplicaSet 的状态:
kubectl get replicaset -n kiamol-ch12-memory
# 查看 RepicaSet 的 events:
kubectl describe replicaset -n kiamol-ch12-memory
您将从 ReplicaSet 的输出中看到,它有 0 个pod,而所需的总数是 1 个。它不能创建 Pod,因为它会超过命名空间的配额,如图12.14所示。控制器一直尝试创建Pod,但它不会成功,除非有足够的配额可用,比如其他 Pod 终止,但在这种情况下,没有任何配额,因此需要更新配额。Kubernetes还可以将CPU限制应用于容器和配额,但它们的工作方式略有不同。具有CPU限制的容器以固定数量的处理能力运行,并且它们可以使用任意数量的CPU—如果达到限制,则不会替换它们。您可以将容器限制为CPU核心的一半,它可以在100% CPU的情况下运行,而节点上的所有其他内核保持空闲并可用于其他容器。计算Pi是一个计算密集型操作,我们可以看到在书中之前使用过的Pi应用程序上应用CPU限制的影响。

现在试试吧,在有和没有CPU限制的情况下运行Pi应用程序,并比较其性能。
# 显示节点可用的总CPU:
kubectl get nodes -o jsonpath='{.items[].status.allocatable.cpu}'
# 部署Pi没有任何CPU限制:
kubectl apply -f pi/
# 获取访问 url:
kubectl get svc pi-web -o jsonpath='http://{.status.loadBalancer
.ingress[0].*}:8012/?dp=50000'
# 浏览到URL,并查看计算需要多长时间
# 现在更新Pod spec 与CPU限制:
kubectl apply -f pi/update/web-with-cpu-limit.yaml
# 刷新Pi应用程序,看看计算需要多长时间
我的输出如图12.15所示。计时将有所不同,这取决于您的节点上有多少CPU可用。我的应用有8个内核,而且没有限制,它能在3.4秒内连续计算圆周率到小数点后5万位。更新后,应用程序容器被限制为一个核心的四分之一,同样的计算需要14.4秒。

Kubernetes 使用一个固定的单位来定义 CPU 限制,其中一个代表一个单核。你可以使用倍数来让你的应用程序容器访问多个内核,或者将单个内核划分为“毫核”,其中一毫核是一个内核的千分之一。清单12.8显示了应用于上一练习中的Pi容器的CPU限制,其中250毫核是一个核的四分之一。
清单 12.8 web-with-cpu-limit.yaml
spec:
containers:
- image: kiamol/ch05-pi
command: ["dotnet", "Pi.Web.dll", "-m", "web"]
resources:
limits:
cpu: 250m # 250 豪核限制容器占用 四分之一核
我一次只关注一种资源,这样你就能清楚地看到影响,但通常你应该包括CPU和内存的限制,这样你的应用程序就不会激增和耗尽集群。资源 specs 还可以包括请求部分,它说明容器预计使用多少CPU和内存。这有助于Kubernetes决定哪个节点应该运行Pod,我们将在第18章讨论调度时详细介绍。
我们将用另一个练习来结束本章,演示如何将CPU限制应用于名称空间的配额,以及超过配额时的含义。Pi应用程序的新规范尝试在一个具有最大500毫核配额的命名空间中运行两个具有300毫核CPU限制的副本。
现在试试吧,在其自己的命名空间中运行更新后的Pi应用程序,该名称空间应用了CPU配额。
# 删除存量 app:
kubectl delete deploy pi-web
# 部署 namespace, quota, 以及新的 app spec:
kubectl apply -f pi/namespace-with-quota/
# 输出 ReplicaSet status:
kubectl get replicaset -n kiamol-ch12-cpu
# 列出 Service 的 endpoints:
kubectl get endpoints pi-web -n kiamol-ch12-cpu
# 显示 RepicaSet 的 events:
kubectl describe replicaset -n kiamol-ch12-cpu
在本练习中,您可以看到配额应用于命名空间中的所有 pod。ReplicaSet 使用一个Pod而不是两个Pod运行,因为第一个Pod分配了 300m CPU,只剩下 200m 的配额—不足以让第二个Pod运行。图 12.16 显示了ReplicaSet事件中的失败原因。Pi应用程序仍在运行,但容量不足,因为没有足够的CPU可用。

配额更多的是为了保护你的集群而不是应用本身,但它们是一种强制所有 Pod spec 都有指定限制的好方法。如果您没有使用命名空间划分集群,您仍然可以对默认命名空间应用具有较大 CPU 和内存限制的配额,以确保 Pod spec 包含它们自己的限制。
资源限制、容器探测和原子升级都有助于保持应用程序在正常故障条件下运行。这些应该在您的生产路线图上,但您也需要意识到Kubernetes不能修复所有类型的故障。
12.5 了解自我修复应用的局限性
Kubernetes 将 Pod 分配给一个节点,这就是它将运行的节点。除非节点离线,否则 pod 不会被替换,因此我们在本章中看到的所有修复机制都是通过重新启动 pod 来工作的——替换应用程序容器。你需要确保你的应用程序可以容忍这种情况,特别是在我们在第7章中介绍的多容器场景中,因为 init 容器会再次执行,当 Pod 重新启动时,sidecars 会被替换。
对于大多数暂时失败的场景,Pod 重新启动是很好的,但重复失败将以 CrashLoopBackOff 状态结束,这可能会使应用程序离线。Kubernetes 没有提供任何关于允许重启多少次或回退周期的配置选项,并且它不支持在不同的节点上用新 Pod 替换失败的 Pod。这些功能是需要的,但在它们着陆之前,你精心配置的自我修复应用程序仍然有可能使所有 Pods 处于回退状态,服务中没有端点。
这种边缘情况通常是由于配置错误的 spec 或应用程序的致命问题而出现的,这些问题需要 Kubernetes 本身无法处理的干预。对于典型的失败状态,容器探测和资源限制的组合对于保持应用程序自身平稳运行大有帮助。这就是自我修复应用程序的全部内容,所以我们可以整理集群,为实验室做准备。
现在试试吧,从本章中移除对象。
# 删除 namespaces:
kubectl delete ns -l kiamol=ch12
kubectl delete all -l kiamol=ch12
# 删除其余对象:
kubectl delete secret,configmap,pvc -l kiamol=ch12
12.6 实验室
在这个实验室里,我为你们准备了一个很好的能力规划练习。目标是将集群划分为三个环境来运行 Pi 应用程序:开发环境、测试环境和UAT环境。UAT应限制在节点总CPU的50%,开发和测试各占25%。你的Pi部署应该设置限制,以便在每个环境中至少可以运行四个副本,然后你需要验证在UAT中可以扩展到多少。
- 首先在实验室文件夹中部署命名空间和服务。
- 然后计算出您的节点的 CPU 容量,并部署资源配额来限制每个命名空间的CPU(您需要编写配额规格)。
- 更新 web 部署规范。yaml包含一个 CPU 限制,允许在每个命名空间中运行四个副本。
- 当一切都在运行时,将UAT部署扩展到8个副本,并尝试找出它们不能全部运行的原因。
这是一个很好的练习,可以帮助您理解如何共享 CPU 资源,并练习如何使用多个命名空间。我的解决方案在GitHub上,你可以查看: https://github.com/yyong-brs/learn-kubernetes/tree/master/kiamol/ch12/lab/README.md。