38 KiB
第五章 通过 volumes,mounts,claims 存储数据
在集群环境中访问数据是困难的。计算的移动是简单的部分,Kubernetes API与节点保持着持续的联系,如果一个节点停止响应,Kubernetes就会认为它已离线,并在其他节点上为其所有Pod启动替代品。但如果其中一个Pod中的应用程序将数据存储在节点上,那么在其他节点上启动时,替代品将无法访问该数据,如果该数据包含客户尚未完成的大订单,那将是令人失望的。你真的需要全集群存储,这样Pod就可以从任何节点访问相同的数据。
Kubernetes 没有内置集群范围的存储,因为没有一个解决方案适用于所有场景。应用程序有不同的存储需求,可以运行Kubernetes的平台有不同的存储能力。数据始终是访问速度和持久性之间的平衡,Kubernetes支持这一点,它允许您定义集群提供的不同存储类(storage class),并为应用程序请求特定的存储类。在本章中,您将学习如何使用不同类型的存储,以及Kubernetes如何抽象出存储实现细节。
5.1 Kubernetes 如何构建容器文件系统
Pod 中的容器的文件系统由Kubernetes使用多个源构建。容器镜像提供文件系统的初始内容,并且每个容器都有一个可写存储层,用于从镜像写入新文件或更新任何文件。(Docker镜像是只读的,所以当容器从镜像中更新文件时,它实际上是在自己的可写层中更新文件的副本。)图5.1显示了Pod内部的情况。
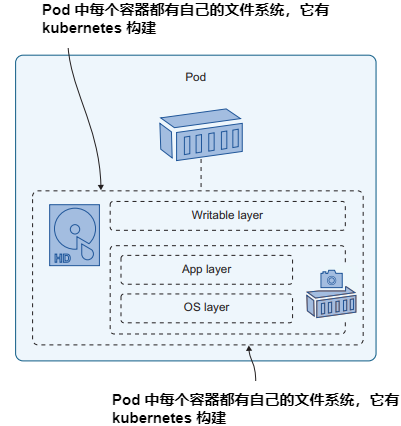
在容器中运行的应用程序只看到一个它具有读写访问权限的文件系统,所有这些层的细节都是隐藏的。这对于将应用程序迁移到Kubernetes来说是很好的,因为它们不需要更改就可以在Pod中运行。但如果你的应用确实需要写入数据,你需要了解它们如何使用存储并设计Pods来支持它们的需求。否则,你的应用程序看起来运行正常,但当任何意外发生时(如使用新容器重新启动Pod),你将面临数据丢失的风险。
现在就试试 如果容器内的应用程序崩溃并且容器退出,Pod将开始替换。新容器将从容器镜像和新的可写层开始从文件系统开始,前一个容器在其可写层中写入的任何数据都将消失。
# 进入本章练习目录:
cd ch05
# 部署一个 sleep Pod:
kubectl apply -f sleep/sleep.yaml
# 在容器内写入一个文件:
kubectl exec deploy/sleep -- sh -c 'echo ch05 > /file.txt; ls /*.txt'
# 检查容器 id:
kubectl get pod -l app=sleep -o jsonpath='{.items[0].status.containerStatuses[0].containerID}'
# kill 容器中所有的进程, 触发 Pod 重启:
kubectl exec -it deploy/sleep -- killall5
# 检查替换的容器 id:
kubectl get pod -l app=sleep -o jsonpath='{.items[0].status.containerStatuses[0].containerID}'
# 查看你之前写入的文件,已经不存在:
kubectl exec deploy/sleep -- ls /*.txt
在这个练习中记住两件重要的事情:Pod容器的文件系统具有容器的生命周期而不是Pod,并且当Kubernetes谈论Pod重启时,它实际上指的是一个替换容器。如果您的应用程序愉快地在容器中写入数据,这些数据不会存储在Pod级别,如果Pod使用新容器重新启动,所有数据都将消失。输出如图5.2所示。

我们已经知道 Kubernetes 可以从其他来源构建容器文件系统,我们在第 4 章中提到过ConfigMaps和Secrets文件系统目录。其机制是在Pod级别定义一个卷,使另一个存储源可用,然后将其挂载到容器文件系统的指定路径上。ConfigMaps和Secrets 是只读存储单元,但Kubernetes支持许多其他类型的可写卷。图5.3展示了如何设计一个Pod,使用卷来存储重启之间的数据,甚至可以在整个集群范围内访问。
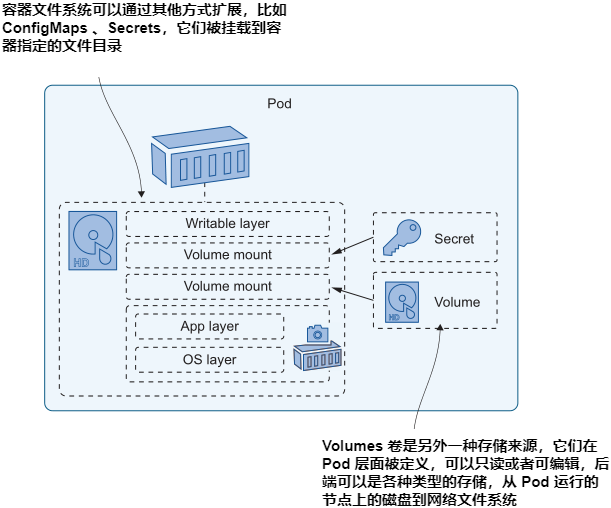
我们将在本章的后面讨论集群范围的卷,但现在,我们将从一个更简单的卷类型开始,这对许多场景仍然有用。清单5.1显示了一个Pod 配置,它使用了一种名为 EmptyDir 的卷类型,这只是一个空目录,但是它存储在Pod级别而不是容器级别。它作为一个卷被挂载到容器中,因此它作为一个目录可见,但它不是镜像层或容器层之一。
清单 5.1 sleep-with-emptyDir.yaml, 一个简单的 volume 配置
spec:
containers:
- name: sleep
image: kiamol/ch03-sleep
volumeMounts:
- name: data # 挂载一个名为 data 的卷
mountPath: /data # 挂载到 /data 目录
volumes:
- name: data # 这个就是 data 卷配置,
emptyDir: {} # 指定 EmptyDir 类型.
空目录听起来是你能想到的最没用的存储空间,但实际上它有很多用途,因为它与Pod具有相同的生命周期。任何存储在EmptyDir卷中的数据都会在重启之间保留在Pod中,这样替换容器就可以访问前一个容器写入的数据。
现在就试试 使用代码清单 5.1 中的配置更新 sleep 部署,添加一个EmptyDir卷。现在可以写入数据并杀死容器,替换容器可以读取数据。
# 更新 sleep Pod 使用一个 EmptyDir volume:
kubectl apply -f sleep/sleep-with-emptyDir.yaml
# 查看 volume mount 的内容:
kubectl exec deploy/sleep -- ls /data
# 在空目录下创建一个文件:
kubectl exec deploy/sleep -- sh -c 'echo ch05 > /data/file.txt; ls /data'
# 检查容器 ID:
kubectl get pod -l app=sleep -o jsonpath='{.items[0].status.containerStatuses[0].containerID}'
# kill 容器进程:
kubectl exec deploy/sleep -- killall5
# 检查替换的容器 ID:
kubectl get pod -l app=sleep -o jsonpath='{.items[0].status.containerStatuses[0].containerID}'
# 查看 volume 挂载的文件:
kubectl exec deploy/sleep -- cat /data/file.txt
输出如图 5.4 所示。容器只是在文件系统中看到一个目录,但它指向一个存储单元,它是Pod的一部分。

任何使用文件系统作为临时存储的应用程序都可以使用 EmptyDir 卷——也许你的应用程序会调用一个API,这个API需要几秒钟才能响应,而且响应需要很长一段时间。应用程序可能会将API响应保存在本地文件中,因为从磁盘读取比重复调用API更快。EmptyDir卷是本地缓存的一个合理来源,因为如果应用程序崩溃,那么替换容器仍然拥有缓存的文件,仍然可以从速度提升中受益。
EmptyDir 卷只共享Pod的生命周期,所以如果替换了Pod,那么新的Pod就从一个空目录开始。如果你希望数据在Pods之间持久化,那么你可以挂载其他类型的卷,它们有自己的生命周期。
5.2 在节点使用 volumes 及 mounts 存储数据
这是数据处理比计算处理更为复杂的地方,因为我们需要考虑数据是否与特定节点相关联 - 这意味着任何替换 Pod 都需要在该节点上运行以查看数据 - 或数据是否具有集群范围的访问权限,并且 Pod 可以在任何节点上运行。Kubernetes 支持许多变体,但您需要知道您想要什么以及集群支持什么,并为 Pod 指定。
最简单的存储选项是使用映射到节点上目录的卷,这样当容器写入卷挂载时,数据实际上存储在节点磁盘上的一个已知目录中。我们将通过运行一个使用EmptyDir卷缓存数据的实际应用程序来演示这一点,了解其限制,然后将其升级为使用节点级存储。
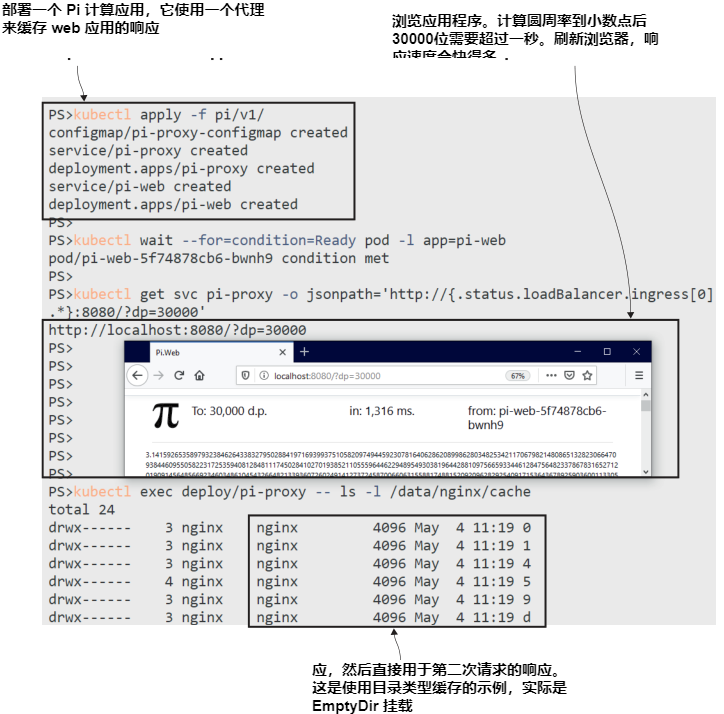
现在就试试 运行一个使用代理组件来提高性能的web应用程序。web应用程序运行在一个带有内部服务的Pod中,代理运行在另一个Pod中,该Pod通过LoadBalancer服务公开可用。
# 部署 Pi 应用:
kubectl apply -f pi/v1/
# 等待 web Pod ready:
kubectl wait --for=condition=Ready pod -l app=pi-web
# 从 LoadBalancer 获取应用 URL:
kubectl get svc pi-proxy -o jsonpath='http://{.status.loadBalancer.ingress[0].*}:8080/?dp=30000'
# 访问 URL, 等待响应然后刷新页面
# 检查 proxy 中的缓存
kubectl exec deploy/pi-proxy -- ls -l /data/nginx/cache
这是 web 应用程序的常见设置,其中代理通过直接从本地缓存中提供响应来提高性能,这也减少了web应用程序的负载。你可以在图5.5中看到我的输出。第一个Pi计算花费了1秒多的时间来响应,并且刷新实际上是即时的,因为它来自代理,不需要计算。
对于这样的应用程序来说,EmptyDir卷可能是一种合理的方法,因为存储在卷中的数据不是关键数据。如果Pod重启,缓存会存活下来,新的代理容器可以为前一个容器缓存的响应提供服务。如果Pod被替换,那么缓存就会丢失。替换的Pod从一个空的缓存目录开始,但缓存不是必需的——应用程序仍然可以正常运行;它只是缓慢地开始,直到缓存再次被填充。
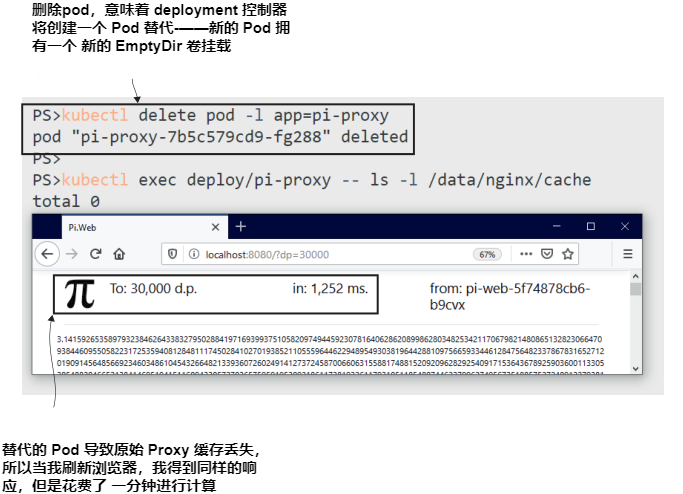
现在就试试 移除 proxy Pod。它将被替换,因为它由部署控制器管理。替换从一个新的EmptyDir卷开始,对于这个应用程序来说,这意味着一个空的代理缓存,因此请求被发送到web Pod。
# 删除 proxy Pod:
kubectl delete pod -l app=pi-proxy
# 检查替换的 Pod 缓存目录:
kubectl exec deploy/pi-proxy -- ls -l /data/nginx/cache
# 刷新界面
输出如图 5.6 所示。结果是相同的,但我不得不等待另一秒,以等待web应用程序计算,因为替换代理Pod启动时没有缓存。
下一个级别的持久性来自于使用映射到节点磁盘上目录的卷,Kubernetes将其称为HostPath卷。hostpath被指定为Pod中的一个卷,它以通常的方式装载到容器文件系统中。容器将数据写入挂载目录时,实际上是将数据写入节点上的磁盘。图5.7展示了node、Pod和volume之间的关系。
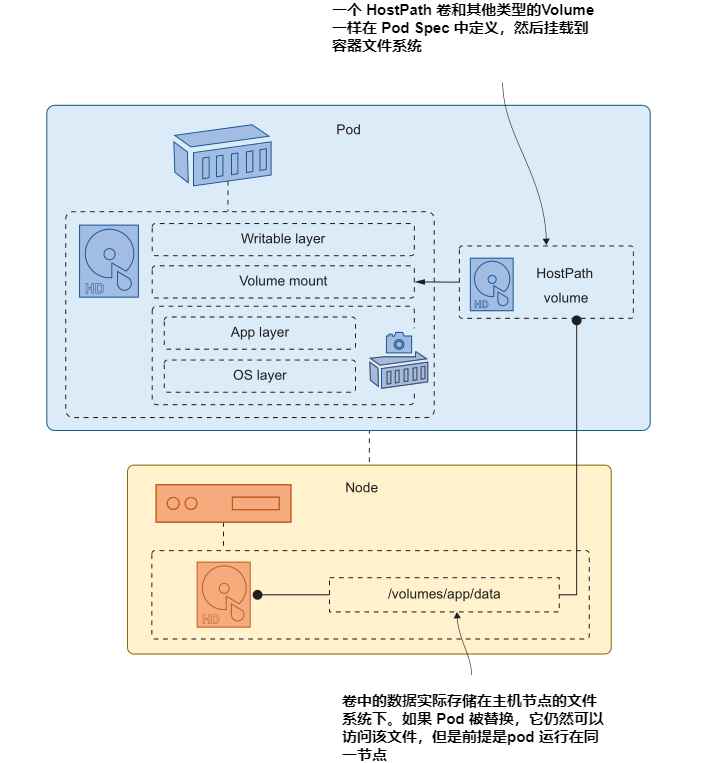
HostPath 卷可能很有用,但您需要了解它们的局限性。数据物理存储在节点上,仅此而已。Kubernetes不会神奇地将数据复制到集群中的所有其他节点。代码清单5.2是更新后的Pod 配置,它使用HostPath卷代替了EmptyDir。当代理容器将缓存文件写入/data/nginx/cache时,它们实际上会存储在节点上的目录 /volumes/nginx/cache。
清单 5.2 nginx-with-hostPath.yaml, 挂载 HostPath volume
spec:
containers: # 完整的配置 还包含一个configMap卷挂载
- image: nginx:1.17-alpine
name: nginx
ports:
- containerPort: 80
volumeMounts:
- name: cache-volume
mountPath: /data/nginx/cache # proxy 缓存路径
volumes:
- name: cache-volume
hostPath: # 使用节点上的目录
path: /volumes/nginx/cache # 节点路径
type: DirectoryOrCreate # 不存在则创建路径
这种方法将数据的持久性从Pod的生命周期扩展到节点磁盘的生命周期,前提是替换Pod总是在同一个节点上运行。在单节点的实验室集群中会出现这种情况,因为只有一个节点。替换Pod将在启动时加载HostPath卷,如果它使用前一个Pod的缓存数据填充,那么新的代理可以立即开始提供缓存数据。
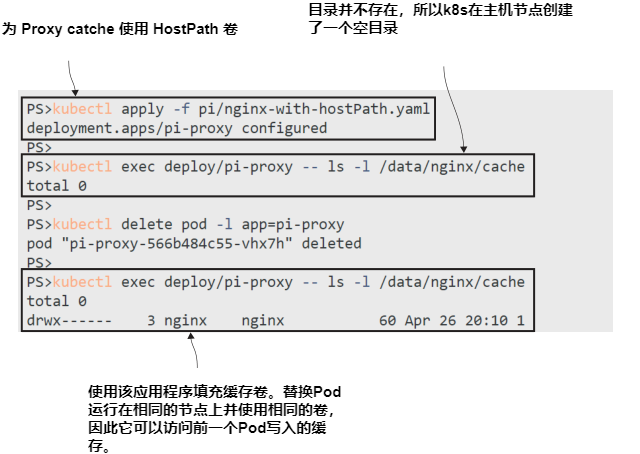
现在就试试 更新 proxy 部署以使用清单5.2中的Pod 配置,然后使用应用程序并删除Pod。替换将使用现有缓存进行响应。
# 更新 proxy Pod 使用 HostPath volume:
kubectl apply -f pi/nginx-with-hostPath.yaml
# 列出缓存目录内容:
kubectl exec deploy/pi-proxy -- ls -l /data/nginx/cache
# 访问 app URL
# 删除 proxy Pod:
kubectl delete pod -l app=pi-proxy
# 检查替换 Pod 下的缓存目录:
kubectl exec deploy/pi-proxy -- ls -l /data/nginx/cache
# 刷新浏览器
输出如图5.8所示。最初的请求只花了不到一秒的时间来响应,但刷新几乎是即时的,因为新的Pod继承了旧Pod缓存的响应,并存储在节点上。
HostPath卷的一个明显的问题是,它们在有多个节点的集群中没有意义,几乎每个集群都有一个简单的实验室环境。你可以在Pod 配置中包含一个要求,要求Pod应该始终运行在同一个节点上,以确保它与数据在一起,但这样做限制了你的解决方案的弹性——如果节点离线,Pod将无法运行,你的应用程序将丢失。
一个不太明显的问题是,该方法提供了一个很好的安全漏洞。Kubernetes没有限制节点上的哪些目录可用于HostPath卷。代码清单5.3中的Pod配置是完全有效的,它使得Pod容器可以访问该节点上的整个文件系统。
清单 5.3 sleep-with-hostPath.yaml, 一个可以完全访问节点磁盘的 Pod
spec:
containers:
- name: sleep
image: kiamol/ch03-sleep
volumeMounts:
- name: node-root
mountPath: /node-root
volumes:
- name: node-root
hostPath:
path: / # 节点文件系统的根目录
type: Directory # 目录必须存在.
任何有权限根据该配置创建Pod的人现在都可以访问Pod运行所在节点的整个文件系统。你可能想使用这样的卷挂载来快速读取主机上的多个路径,但如果你的应用程序受到攻击,攻击者可以在容器中执行命令,那么他们也可以访问节点的磁盘。
现在就试试 运行代码清单 5.3 中的YAML文件中的Pod,然后在 Pod 容器中运行一些命令来浏览node的文件系统。
# 运行一个带卷挂载到主机的Pod:
kubectl apply -f sleep/sleep-with-hostPath.yaml
# 检查容器内的日志文件:
kubectl exec deploy/sleep -- ls -l /var/log
# 检查卷所在节点的日志:
kubectl exec deploy/sleep -- ls -l /node-root/var/log
# 检查容器用户:
kubectl exec deploy/sleep -- whoami
如图 5.9 所示,Pod容器可以看到节点上的日志文件,在本例中包括Kubernetes日志。这是相当无害的,但是这个容器以root用户的身份运行,该用户映射到节点上的root用户,因此容器可以完全访问文件系统。

如果这一切看起来像是一个糟糕的想法,请记住Kubernetes是一个具有广泛功能的平台,可以适应许多应用程序。您可能有一个旧的应用程序,需要访问其运行节点上的特定文件路径,而HostPath卷允许您这样做。在这种情况下,您可以采用一种更安全的方法,使用可以访问节点上一条路径的卷,通过声明卷挂载的子路径来限制容器可以看到的内容。清单5.4显示了这一点。
清单 5.4 sleep-with-hostPath-subPath.yaml, 用子路径限制挂载
spec:
containers:
- name: sleep
image: kiamol/ch03-sleep
volumeMounts:
- name: node-root # 挂载的卷名称
mountPath: /pod-logs # 容器的路径
subPath: var/log/pods # 卷内的路径
- name: node-root
mountPath: /container-logs
subPath: var/log/containers
volumes:
- name: node-root
hostPath:
path: /
type: Directory
在这里,卷仍然定义在节点的根路径上,但访问它的唯一方式是通过容器中的卷挂载,这些挂载仅限于定义的子路径。在volume 配置和mount 配置之间,在构建和映射容器文件系统方面有很大的灵活性。
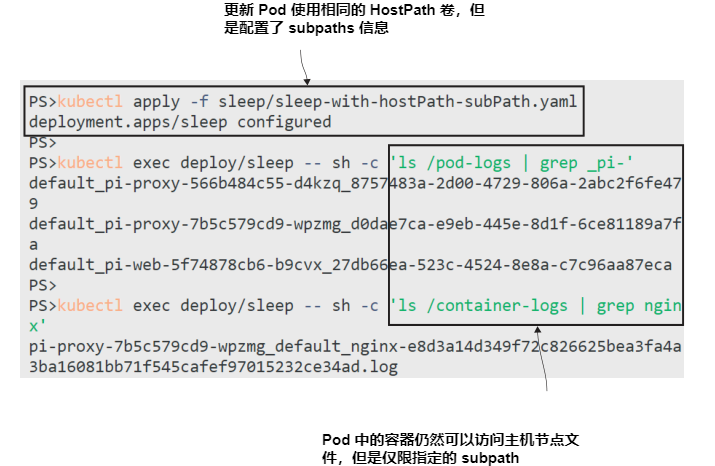
现在就试试 更新sleep Pod,使容器的卷挂载限制在清单5.4中定义的子路径中,并检查文件内容。
# 更新 Pod spec:
kubectl apply -f sleep/sleep-with-hostPath-subPath.yaml
# 检查 node 上 Pod 日志:
kubectl exec deploy/sleep -- sh -c 'ls /pod-logs | grep _pi-'
# 检查容器日志 logs:
kubectl exec deploy/sleep -- sh -c 'ls /container-logs | grep nginx'
在这个练习中,除了通过挂载到日志目录之外,没有其他方法可以查看节点的文件系统。如图 5.10 所示,容器只能访问子路径中的文件。 HostPath卷是创建有状态应用程序的好方法;它们易于使用,并且在任何集群上都以相同的方式工作。它们在现实世界的应用程序中也很有用,但只有当你的应用程序使用状态作为临时存储时才有用。对于永久存储,我们需要迁移到集群中任何节点都可以访问的卷。
5.3 使用 persistent volumes 及 claims 存储集群范围数据
Kubernetes 集群就像一个资源池:它有许多节点,每个节点都有一些 CPU 和内存容量供集群使用,Kubernetes使用它们来运行你的应用程序。存储只是Kubernetes提供给你的应用程序的另一种资源,但只有当节点可以插入分布式存储系统时,它才能提供集群范围的存储。图 5.11 展示了如果卷使用分布式存储,Pods 如何从任何节点访问卷。
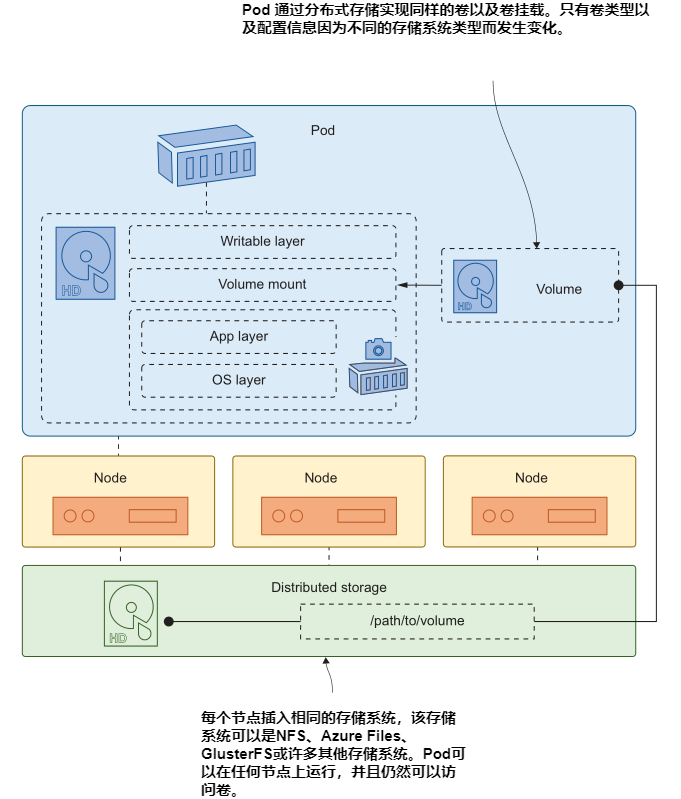
Kubernetes 支持由分布式存储系统支持的许多卷类型: AKS集群可以使用 Azure 文件或 Azure 磁盘,EKS集群可以使用弹性块存储,并且在数据中心,您可以使用简单的网络文件系统(NFS)共享,或像 GlusterFS 这样的网络文件系统。所有这些系统都有不同的配置要求,您可以在 Pod 的卷配置中指定它们。这样做将使您的应用程序配置与一种存储实现紧密耦合,Kubernetes提供了一种更灵活的方法。
Pods 是位于计算层之上的抽象,而Services是位于网络层之上的抽象。在存储层中,抽象是PersistentVolumes (PV)和PersistentVolumeClaims。PersistentVolume是一个Kubernetes对象,它定义了一个可用的存储空间。集群管理员可以创建一组持久化卷,其中每个卷包含底层存储系统的卷规格。代码清单5.5展示了使用NFS存储的 PersistentVolume 配置。
清单 5.5 persistentVolume-nfs.yaml, 由NFS挂载支持的卷
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv01 # 具有通用名称的通用存储单元
spec:
capacity:
storage: 50Mi # PV 提供的存储空间
accessModes: # 如何通过Pods访问卷
- ReadWriteOnce # 它只能被一个Pod使用。
nfs: # 该PV由NFS支持.
server: nfs.my.network # NFS 服务的域名
path: "/kubernetes-volumes" # NFS 共享的路径
您无法在实验室环境中部署该配置,除非您的网络中恰好有一个NFS服务器,其域名为 nfs.my.network,共享名为 kubernetes-volumes。您可以在任何平台上运行Kubernetes,因此在接下来的练习中,我们将使用可以在任何地方工作的本地卷。(如果我在练习中使用Azure文件,它们只能在AKS集群上工作,因为EKS和Docker Desktop以及其他Kubernetes发行版没有为Azure卷类型配置。)
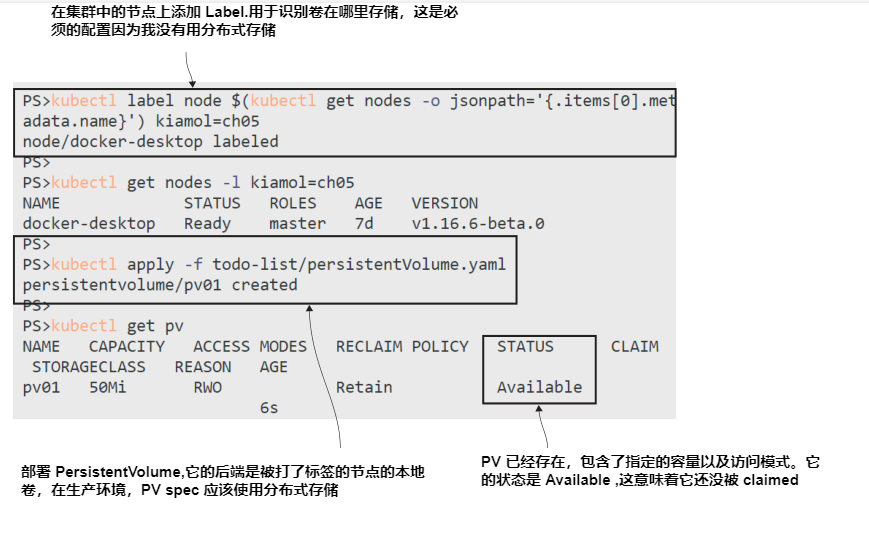
现在就试试 创建一个使用本地存储的 PV。PV是集群范围内的,但卷是本地的一个节点,因此我们需要确保PV连接到卷所在的节点。我们用标签来做。
# 将自定义标签应用到集群中的第一个节点:
kubectl label node $(kubectl get nodes -o jsonpath='{.items[0].metadata.name}') kiamol=ch05
# 使用标签选择器检查节点:
kubectl get nodes -l kiamol=ch05
# 在标记的节点上部署一个使用本地卷的PV:
kubectl apply -f todo-list/persistentVolume.yaml
# 检查 PV:
kubectl get pv
输出如图5.12所示。节点标记是必要的,因为我没有使用分布式存储系统;您通常只需要指定NFS或Azure磁盘卷配置,这些配置可以从任何节点访问。本地卷仅存在于一个节点上,PV使用标签标识该节点。
现在 PV 作为一个可用的存储单元存在于集群中,具有一组已知的特性,包括大小和访问模式。pod不能直接使用PV;相反,他们需要使用PersistentVolumeClaim (PVC)来声明它。PVC是Pods使用的存储抽象,它只是为应用程序请求一些存储空间。Kubernetes将PVC与PV匹配,并将底层的存储细节留给PV。代码清单5.6展示了一个与我们创建的PV相匹配的存储空间声明。
清单 5.6 postgres-persistentVolumeClaim.yaml, PVC 匹配 PV
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-pvc # 该声明将由特定的应用程序使用。
spec:
accessModes: # 必要的 access mode
- ReadWriteOnce
resources:
requests:
storage: 40Mi # 请求的存储大小
storageClassName: "" # 一个空白类意味着PV需要存在.
PVC 配置包括访问模式、存储量和存储类。如果没有指定存储类,Kubernetes会尝试找到与声明中要求匹配的现有PV。如果有匹配,则PVC绑定到PV—有一对一的链接,一旦PV 被声明使用,就不能供任何其他PVC使用。
现在就试试 部署代码清单 5.6 中的PVC。它的要求由我们在前一个练习中创建的 PV 满足,因此 claim 将绑定到该 volume。
# 创建一个绑定到 pv 的pvc:
kubectl apply -f todo-list/postgres-persistentVolumeClaim.yaml
# 检查 PVCs:
kubectl get pvc
# 检查 PVs:
kubectl get pv
我的输出出现在图 5.13 中,在这里可以看到一对一的绑定:PVC 绑定到卷,PV 绑定到 claim。

这是一种静态配置方法,PV 需要显式创建,以便Kubernetes可以绑定到它。如果在创建PVC时没有匹配的PV,则仍然创建了声明,但它是不可用的。它将停留在系统中,等待满足其要求的PV被创建。
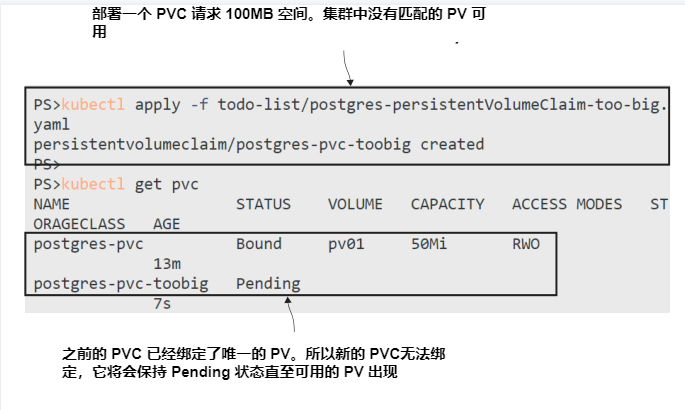
现在就试试 集群中的 PV 已经绑定到某个 claim ,因此不能再次使用。创建另一个PVC,将保持未绑定
# 创建一个不匹配任何可用 PV 的 PVC:
kubectl apply -f todo-list/postgres-persistentVolumeClaim-too-big.yaml
# 检查 claims:
kubectl get pvc
在图 5.14 中可以看到新的 PVC 处于挂起状态。这种情况会一直持续下去,直到集群中出现一个容量至少为100 MB的PV(即本声明中的存储需求)。
在 Pod 使用PVC之前,需要先把它绑起来。如果你部署了一个引用未绑定PVC的Pod,在PVC绑定之前Pod将保持挂起状态,因此你的应用程序将永远无法运行,直到它拥有所需的存储空间。我们创造的第一个PVC已经绑定,所以它可以使用,但只能绑定到一个 Pod。声明的访问模式是ReadWriteOnce,这意味着卷是可写的,但只能由一个Pod挂载。代码清单5.7是Postgres数据库的简短Pod 配置,使用PVC存储。
清单 5.7 todo-db.yaml, 一个 Pod 配置消费 PVC**
spec:
containers:
- name: db
image: postgres:11.6-alpine
volumeMounts:
- name: data
mountPath: /var/lib/postgresql/data
volumes:
- name: data
persistentVolumeClaim: # 卷使用某 PVC
claimName: postgres-pvc # 使用的 pvc
现在我们已经准备好了使用卷部署Postgres数据库Pod的所有部件,卷可能支持也可能不支持分布式存储。应用程序设计人员拥有Pod 配置和PVC,并不关心pv——pv依赖于Kubernetes集群的基础设施,可以由不同的团队管理。在我们的实验室环境中,我们拥有一切。我们还需要采取另一个步骤:在卷预期使用的节点上创建目录路径。
现在就试试 你可能无法登录到真正的Kubernetes集群中的节点,所以我们在这里通过运行sleep Pod来作弊,它将HostPath挂载到节点的根目录,并使用挂载创建目录。
# 运行 sleep Pod, 它可以访问节点磁盘:
kubectl apply -f sleep/sleep-with-hostPath.yaml
# 等待 Pod ready:
kubectl wait --for=condition=Ready pod -l app=sleep
# 创建节点的目录, 来自 PV 指定的值:
kubectl exec deploy/sleep -- mkdir -p /node-root/volumes/pv01
图 5.15 展示了以 root 权限运行的 sleep Pod,因此它可以在节点上创建目录,即使我没有直接访问该节点的权限。

现在一切都准备好了,可以使用持久存储运行待办事项列表应用程序。通常情况下,你不需要经历这么多步骤,因为你知道集群提供的功能。不过,我不知道你的集群能做什么,所以这些练习可以在任何集群上运行,它们是对所有存储资源的有用介绍。图5.16展示了到目前为止部署的内容,以及即将部署的数据库。
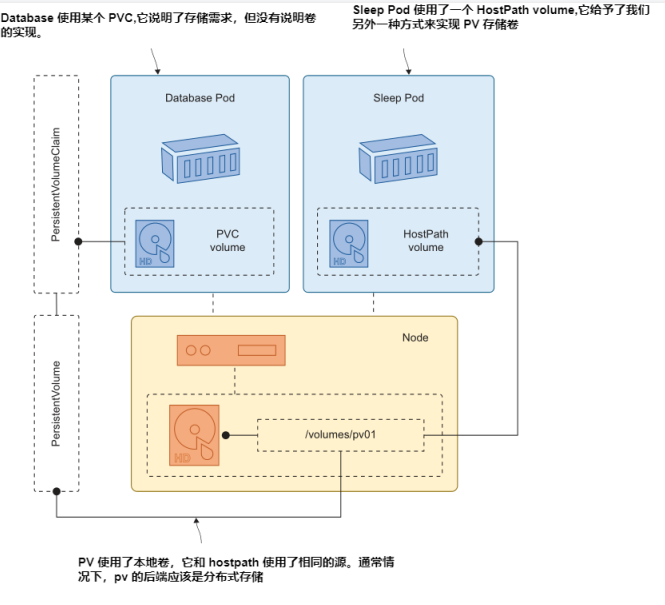
让我们运行数据库。当创建 Postgres 容器时,它将卷挂载到由PVC支持的Pod中。这个新的数据库容器连接到一个空卷,因此当它启动时,它将初始化数据库,创建预写日志(writeahead log, WAL),这是主数据文件。Postgres Pod并不知道,但是PVC是由节点上的本地卷支持的,在这里我们也有一个sleep Pod在运行,我们可以使用它来查看Postgres文件。
现在就试试 部署数据库,并给它时间来初始化数据文件,然后使用sleep Pod检查卷中写入了什么。
# 部署 database:
kubectl apply -f todo-list/postgres/
# 等待 Postgres 初始化:
sleep 30
# 检查 database 日志:
kubectl logs -l app=todo-db --tail 1
# 检查卷中的数据文件:
kubectl exec deploy/sleep -- sh -c 'ls -l /node-root/volumes/pv01 | grep wal'
图 5.17 中的输出显示数据库服务器已经正确启动并等待连接,已经将所有数据文件写入卷中。

最后要做的是运行应用程序,测试它,并确认如果替换了数据库Pod,数据仍然存在。
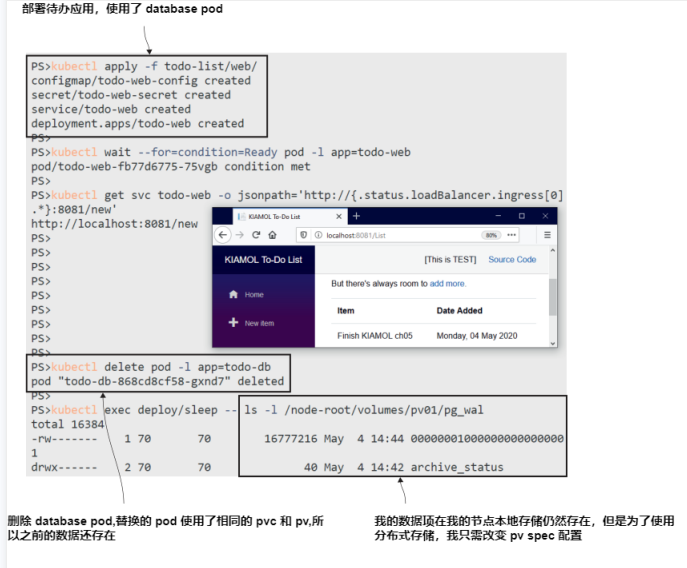
现在就试试 运行待办事项应用程序的web Pod,它连接到Postgres数据库。
# 部署 web app 组件:
kubectl apply -f todo-list/web/
# 等待 web Pod:
kubectl wait --for=condition=Ready pod -l app=todo-web
# 从 Service 获取访问 url:
kubectl get svc todo-web -o jsonpath='http://{.status.loadBalancer.ingress[0].*}:8081/new'
# 访问 app, 添加新的条目
# 删除 database Pod:
kubectl delete pod -l app=todo-db
# 检查 node 上的 卷的内容:
kubectl exec deploy/sleep -- ls -l /node-root/volumes/pv01/pg_wal
# 检查新增加的条目是不是还在 to-do list
在图5.18中,您可以看到我的待办事项应用程序显示了一些数据,您只需相信我的话,这些数据被添加到第一个数据库Pod中,并从第二个数据库Pod中重新加载。
我们现在有了一个很好的解耦应用程序,它有一个web Pod,可以独立于数据库进行更新和扩展,还有一个数据库Pod,它在Pod生命周期之外使用持久存储。本练习使用本地卷作为持久数据的备份存储,但是对于生产部署,惟一需要做的更改是将PV中的卷配置替换为集群支持的分布式卷。
是否应该在 Kubernetes 中运行关系型数据库是我们将在本章末尾解决的问题,但在此之前,我们先来看看真正的存储:让集群根据抽象的存储类动态配置卷。
5.4 动态 volume provisioning 及 storage classes
到目前为止,我们使用的是静态配置过程。我们明确地创建了PV,然后创建了PVC, Kubernetes将其绑定到PV。这适用于所有Kubernetes集群,并且可能是对存储访问受到严格控制的组织的首选工作方式,但大多数Kubernetes平台支持一个更简单的动态配置(dynamic provisioning)替代方案。
在动态配置工作流中,您只需创建PVC,而支持PVC的PV则由集群按需创建。集群可以配置多个存储类,这些存储类反映所提供的不同卷功能,也可以配置一个默认存储类。pvc可以指定他们想要的存储类的名称,或者如果他们想使用默认类,那么他们在声明配置中省略存储类字段,如清单5.8所示。
清单 5.8 postgres-persistentVolumeClaim-dynamic.yaml, 动态 PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-pvc-dynamic
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi
# 没有指定 storageClassName 字段, 所以此处使用 default class.
您可以在不创建 PV 的情况下将这个 PVC 部署到您的集群中—但是我不能告诉您将会发生什么,因为这取决于您的集群的设置。如果您的 Kubernetes 平台支持使用默认存储类的动态配置,那么您将看到一个 PV 被创建并绑定到 PVC,并且该PV将使用集群中配置的默认类型。
现在就试试 部署一个 PVC,并查看它是否是动态供应的。
# 从清单 5.8 部署 PVC:
kubectl apply -f todo-list/postgres-persistentVolumeClaim-dynamic.yaml
# 检查 claims 和 volumes:
kubectl get pvc
kubectl get pv
# 删除 claim:
kubectl delete pvc postgres-pvc-dynamic
# 再次检查卷:
kubectl get pv
当你运行这个练习时会发生什么?Docker Desktop使用默认存储类中的HostPath卷来动态分配 PV;AKS使用Azure文件;K3s使用HostPath,但配置与Docker Desktop不同,这意味着您将看不到 PV,因为它仅在创建使用 PVC 的 Pod 时创建。图5.19显示了Docker Desktop的输出。PV被创建并绑定到PVC,当PVC被删除时,PV也被删除。

Storage class 提供了很大的灵活性。您将它们创建为标准的 Kubernetes 资源,并且在 spec 中,您准确地定义了存储类如何使用以下三个字段
- provisioner—按需创建 PV 的组件。不同的平台有不同的供应器,例如,默认AKS存储类中的供应器与Azure文件集成以创建新的文件共享。
- reclaimPolicy—定义删除 claims 时如何处理动态创建的卷。底层卷也可以被删除,也可以被保留。
- volumeBindingMode—决定是否在 PVC 创建时立即创建PV,或者直到使用PVC的Pod创建时才创建PV。
通过组合这些属性,可以在集群中选择存储类,因此应用程序可以请求所需的属性(从快速本地存储到高可用集群存储),而无需指定卷或卷类型的确切细节。我无法为您提供一个可以在您的集群上工作的存储类YAML,因为集群并不是所有的集群都有相同的可用供应程序。相反,我们将通过克隆默认类来创建一个新的存储类。
现在就试试 获取默认 storage class 并克隆它包含一些令人讨厌的细节,因此我将这些步骤封装在一个脚本中。如果你好奇,你可以检查脚本内容,但之后你可能需要躺下休息一下。
# 查询集群 storage classes :
kubectl get storageclass
# 在 Windows 上 clone 默认的类型:
Set-ExecutionPolicy Bypass -Scope Process -Force;
./cloneDefaultStorageClass.ps1
# 或者在 Mac/Linux:
chmod +x cloneDefaultStorageClass.sh && ./cloneDefaultStorageClass.sh
# 查询 storage classes:
kubectl get sc
从列出存储类中看到的输出显示了集群已配置的内容。运行脚本后,您应该有一个名为 kiamol 的新类型,它具有与默认存储类相同的设置。Docker Desktop的输出如图 5.20 所示。

现在你有了一个自定义存储类,你的应用程序可以在PVC中请求它。这是一种更加直观和灵活的存储管理方式,特别是在动态供应简单快速的云平台中。清单5.9显示了请求新存储类的PVC规范。
清单 5.9 postgres-persistentVolumeClaim-storageClass.yaml
spec:
accessModes:
- ReadWriteOnce
storageClassName: kiamol # 这个存储类型是抽象的
resources:
requests:
storage: 100Mi
生产集群中的存储类将有更有意义的名称,但我们现在在集群中都有一个具有相同名称的存储类,因此我们可以更新Postgres数据库以使用该显式类。
现在就试试 创建新的PVC,并更新数据库Pod Spec 以使用它。
# 使用自定义存储类创建一个新的PVC:
kubectl apply -f storageClass/postgres-persistentVolumeClaim-storageClass.yaml
# 更新数据库以使用新的 PVC:
kubectl apply -f storageClass/todo-db.yaml
# 检查 storage:
kubectl get pvc
kubectl get pv
# 检查 Pods:
kubectl get pods -l app=todo-db
# 刷新 to-do 应用清单
这个练习将数据库 Pod 切换为使用新的动态配置的PVC,如图5.21中的输出所示。新的PVC由一个新的卷支持,因此它将开始为空,您将丢失以前的数据。以前的卷仍然存在,因此您可以将另一个更新部署到数据库Pod,将其恢复到旧的PVC,并查看您的条目。

5.5 理解 Kubernetes 中存储的选择
这就是Kubernetes的存储。在您的日常工作中,您将为 pod 定义PersistentVolumeClaims,并指定所需的大小和存储类,这可以是一个自定义值,如FastLocal或Replicated。在本章中,我们花了很长时间才了解到这一点,因为了解在声明存储时实际发生了什么、涉及到哪些其他资源以及如何配置它们非常重要。
我们还介绍了卷类型,这是您需要深入研究的一个领域,以便了解您的Kubernetes平台上有哪些可用选项以及它们提供哪些功能。如果您处于云环境中,您应该拥有多个集群范围内的存储选项,但请记住存储成本,以及快速存储的成本很高。您需要理解,您可以使用快速存储类创建PVC,这些存储类可以配置为保留底层卷,这意味着您在删除部署时仍然需要支付存储费用。
这给我们带来了一个大问题:你是否应该使用 Kubernetes 来运行像数据库这样的有状态应用程序?这些功能都是为了给你提供高可用性的复制存储(如果你的平台提供的话),但这并不意味着你应该急于退役你的Oracle资产,用运行在Kubernetes中的MySQL来代替它。管理数据给Kubernetes应用程序增加了很多复杂性,而运行有状态应用程序只是问题的一部分。需要考虑数据备份、快照和回滚,如果您在云中运行,托管数据库服务可能会为您提供开箱即用的服务。但是在Kubernetes清单中定义整个堆栈是非常诱人的,而且一些现代数据库服务器被设计为在容器平台中运行;TiDB和CockroachDB是值得一看的选项。
现在剩下的就是在我们进入实验室之前整理您的实验室集群。
现在就试试 从本章使用的清单中删除所有对象。您可以忽略所得到的任何错误,因为在运行此操作时,并非所有对象都将存在。
# 删除 deployments, PVCs, PVs, and Services:
kubectl delete -f pi/v1 -f sleep/ -f storageClass/ -f todo-list/web -f todo-list/postgres -f todo-list/
# 删除自定义 storage class:
kubectl delete sc kiamol
5.6 实验室
这些实验旨在为您提供一些实际Kubernetes问题的经验,因此我不会要求您复制这个练习来克隆默认存储类。相反,我们有一个新的待办事项应用程序部署,它有几个问题。我们在web Pod前使用 Proxy 来提高性能,并在web Pod内使用本地数据库文件,因为这只是一个开发部署。我们需要在代理层和web层配置一些持久存储,这样你可以删除Pods和部署,而数据仍然可以保存。
- 首先在 ch05/lab/todo-list 文件夹中部署应用清单;它为代理和web组件创建 Service 和 Deployment。
- 找到 LoadBalancer 的URL,并尝试使用该应用程序。你会发现它没有响应,你需要深入日志以找出问题所在.
- 您的任务是为 Proxy 缓存文件和web Pod中的数据库文件配置持久存储。您应该能够从日志条目和Pod Spec 中找到挂载目标。
- 当应用程序运行时,你应该能够添加一些数据,删除所有Pods,刷新浏览器,并看到你的数据仍然在那里。
- 您可以使用任何您喜欢的卷类型或存储类。这是一个探索你的平台提供什么的好机会。
我的解决方案像往常一样在GitHub上供你检查,如果你需要: https://github.com/yyong-brs/learn-kubernetes/blob/master/kiamol/ch05/lab/README.md.