33 KiB
第十三章 使用 Fluentd 和 Elasticsearch 集中化日志
应用程序生成大量日志,这些日志通常不是很有用。当您在集群中运行的多个pod上扩展应用程序时,使用标准的Kubernetes工具很难管理这些日志。组织通常部署自己的日志框架,该框架使用收集-转发模型来读取容器日志并将它们发送到中央存储,在那里可以对它们进行索引、筛选和搜索。在本章中,您将学习如何使用该领域最流行的技术:Fluentd和Elasticsearch。Fluentd是一个收集器组件,它与Kubernetes有一些很好的集成;Elasticsearch是存储组件,既可以作为集群中的Pods运行,也可以作为外部服务运行。
在我们开始之前,你应该注意几点。首先,这个模型假设你的应用程序日志被写入容器的标准输出流,这样Kubernetes就可以找到它们。我们在第7章中讨论了这个问题,使用了直接写入标准输出或使用日志sidecar来中继日志的示例应用程序。其次,Kubernetes的日志记录模型与Docker有很大的不同。电子书的附录D向您展示了如何在Docker中使用Fluentd,但在Kubernetes中,我们将采用不同的方法。
13.1 Kubernetes 如何存储日志条目
Kubernetes 有一种非常简单的日志管理方法:它从容器运行时收集日志条目,并将它们作为文件存储在运行容器的节点上。如果您想执行更高级的操作,那么您需要部署自己的日志管理系统,幸运的是,您有一个世界级的容器平台来运行它。日志系统的移动部分从节点收集日志,将它们转发到集中存储,并提供一个UI来搜索和过滤它们。图13.1显示了我们将在本章中使用的技术。
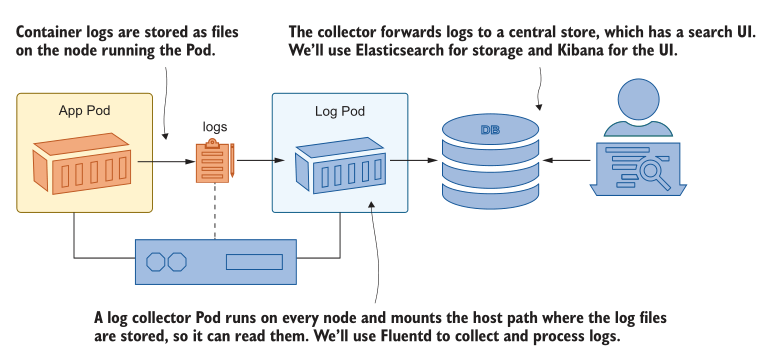
节点使用包含命名空间、Pod和容器名称的文件名存储来自容器的日志条目。标准命名系统使日志采集器很容易向日志条目添加元数据以识别源,而且由于采集器本身作为Pod运行,因此它可以查询Kubernetes API服务器以获得更多详细信息。Fluentd 添加 Pod 标签和镜像标记作为额外的元数据,您可以使用它们过滤或搜索日志。
日志采集器的部署非常简单。我们将探索从节点上的原始日志文件开始,看看我们正在处理什么。这一切的前提是将应用程序日志从容器中取出,无论应用程序直接写入这些日志还是使用sidecar容器。首先将第7章中的timecheck应用部署到几个不同的配置中,以生成一些日志。
现在试试吧,在不同的命名空间中使用不同的设置运行timecheck应用程序,然后检查日志,看看如何在kubectl中本机使用它们。
# 切换到本章目录:
cd ch13
# 在开发和测试命名空间中部署时间检查应用程序:
kubectl apply -f timecheck/
# 等待开发命名空间启动:
kubectl wait --for=condition=ContainersReady pod -l app=timecheck -n kiamol-ch13-dev
# 检查日志:
kubectl logs -l app=timecheck --all-containers -n kiamol-ch13-dev --tail 1
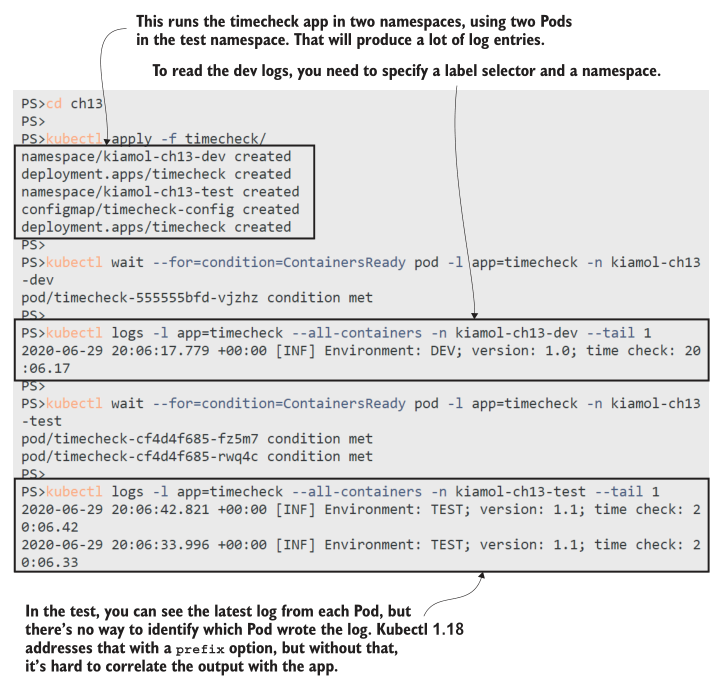
您将从这个练习中看到,在实际的集群环境中,很难直接使用容器日志,如图13.2中的输出所示。一次只能使用一个命名空间,不能识别记录消息的Pod,但可以仅根据日志条目的数量或时间段进行过滤。
Kubectl是读取日志的最简单选项,但最终日志条目来自每个节点上的文件,这意味着您可以使用其他选项来处理日志。本章的源代码包括一个简单的睡眠部署,它将日志路径作为HostPath卷挂载到节点上,即使您没有直接访问节点,也可以使用它来查看日志文件。
现在试试吧,为主机的日志目录运行一个带卷挂载的Pod,并使用挂载浏览文件。
# 运行 Deployment:
kubectl apply -f sleep.yaml
# 连接到 Pod 中的容器会话:
kubectl exec -it deploy/sleep -- sh
# 进入到日志挂载目录:
cd /var/log/containers/
# 查看日志文件:
ls timecheck*kiamol-ch13*_logger*
# 查看 dev log 文件内容:
cat $(ls timecheck*kiamol-ch13-dev_logger*) | tail -n 1
# 退出会话:
exit
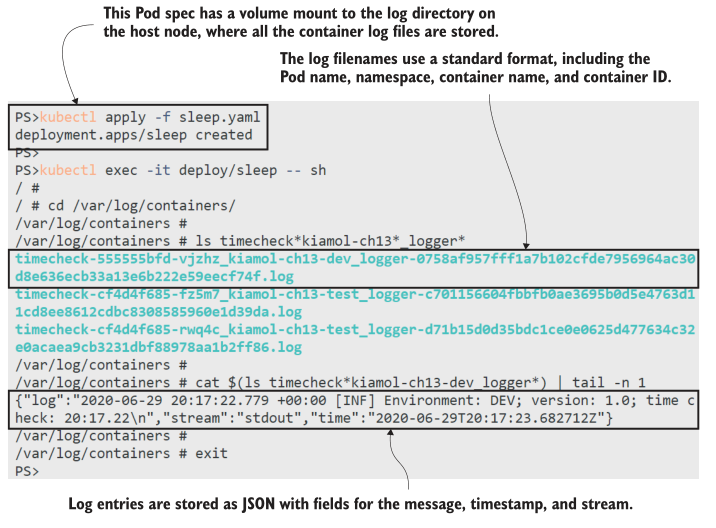
每个 Pod 容器都有一个用于日志输出的文件。timecheck应用程序使用一个名为logger的sidecar容器来从应用程序容器中中继日志,您可以在图13.3中看到Kubernetes为日志文件使用的标准命名约定:pod-name_namespace_container-name-container-id.log。文件名有足够的数据来识别日志的来源,文件的内容是容器运行时输出的原始JSON日志。
Pod重新启动后,日志文件仍会保留,但大多数Kubernetes实现都包括在节点上运行的日志旋转系统(在Kubernetes之外),以防止日志占用所有磁盘空间。收集日志并将其转发到中央存储可以让您更长时间地保存它们,并将日志存储隔离在一个地方—这也适用于来自Kubernetes核心组件的日志。Kubernetes的DNS服务器、API服务器和网络代理都以Pods的方式运行,您可以像查看应用程序日志一样查看和收集它们的日志。
现在试试吧,并不是每个Kubernetes节点都运行相同的核心组件,但是您可以使用sleep Pod查看哪些通用组件正在您的节点上运行。
# 连接一个 Pod 容器:
kubectl exec -it deploy/sleep -- sh
# 进入到主机path 卷目录:
cd /var/log/containers/
# 网络代理服务运行在每个节点上:
cat $(ls kube-proxy*) | tail -n 1
# 如果你使用的是 core dns,你将看到日志:
cat $(ls coredns*) | tail -n 1
# 如果你的节点运行 API server ,你将看到日志:
cat $(ls kube-apiserver*) | tail -n 1
# 退出会话:
exit
您可能会从该练习中得到不同的输出,这取决于您的实验室集群是如何设置的。网络代理Pod运行在每个节点上,所以你应该看到这些日志,但如果你的集群使用CoreDNS(这是默认的DNS插件),你只会看到DNS日志,如果你的节点正在运行API Server,你只会看到API server 日志。我从Docker Desktop的输出如图13.4所示;如果你看到一些不同的东西,你可以运行ls *.log来查看节点上所有的Pod日志文件。

现在您已经了解了Kubernetes是如何处理和存储容器日志的,您可以看到集中式日志系统是如何使故障排除变得更加容易的。收集器在每个节点上运行,从日志文件中抓取条目并转发它们。在本章的其余部分,您将学习如何使用EFK堆栈:Elasticsearch、Fluentd和Kibana实现它。
13.2 使用 Fluentd 收集节点日志
Fluentd 是 CNCF 项目,有很好的基础,是一个成熟的、受欢迎的产品。存在其他日志收集组件,但 Fluentd 是一个很好的选择,因为它具有强大的处理管道来操作和过滤日志条目,以及可插入的体系结构,因此它可以将日志转发到不同的存储系统。它也有两种变体:完整的 Fluentd 快速高效,有1000多个插件,但我们将使用最小的替代品,称为 Fluent Bit。
Fluent Bit 最初是作为 Fluentd 的轻量级版本开发的,用于 IoT 设备等嵌入式应用程序,但它具有在完整的 Kubernetes 集群中进行日志聚合所需的所有功能。每个节点都将运行一个日志采集器,因此保持该组件的影响较小是有意义的,而且Fluent Bit只占用几十兆的内存。Kubernetes 中的 Fluent Bit 架构很简单:DaemonSet 在每个节点上运行一个收集器Pod,它使用 HostPath 卷挂载来访问日志文件,就像在我们使用的睡眠示例中一样。Fluent Bit 支持不同的输出,所以我们将从简单的开始,只是登录到 Fluent Bit Pod 的控制台。
现在试试吧,部署Fluent Bit,配置为读取时间检查日志文件并将其写入Fluent Bit容器的标准输出流。
# 部署 DaemonSet and ConfigMap:
kubectl apply -f fluentbit/
# 等待 Pod 就緒:
kubectl wait --for=condition=ContainersReady pod -l app=fluent-bit -n kiamol-ch13-logging
# 检查 Fluent Bit Pod 日志:
kubectl logs -l app=fluent-bit -n kiamol-ch13-logging --tail 2
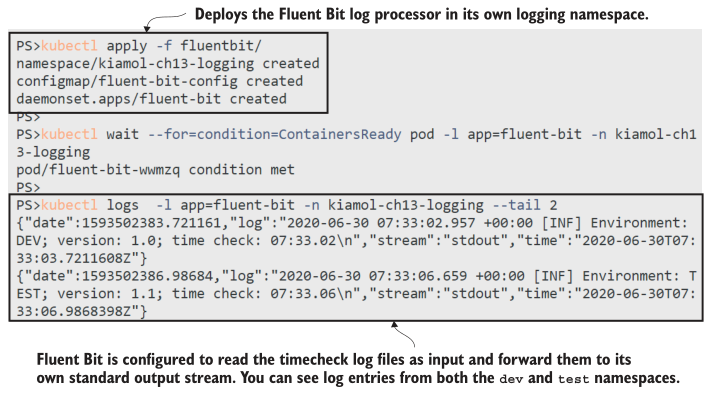
我的输出如图 13.5所示,其中您可以看到来自 timecheck 容器的日志被显示在Fluent Bit容器中。创建日志条目的 pod 位于不同的命名空间中,但是Fluent Bit从节点上的文件中读取它们。内容是原始JSON加上更精确的时间戳,Fluent Bit将其添加到每个日志条目中。
在 Fluent Bit 的 DaemonSet spec 中,您已经看到了所有内容。我使用单独的命名空间进行日志记录,因为您通常希望它作为集群上运行的所有应用程序所使用的共享服务运行,而命名空间是隔离所有对象的好方法。运行Fluent Bit pod很简单——复杂之处在于配置日志处理管道,我们需要深入研究这一点,以充分利用日志模型。图13.6显示了管道的各个阶段以及如何使用它们。
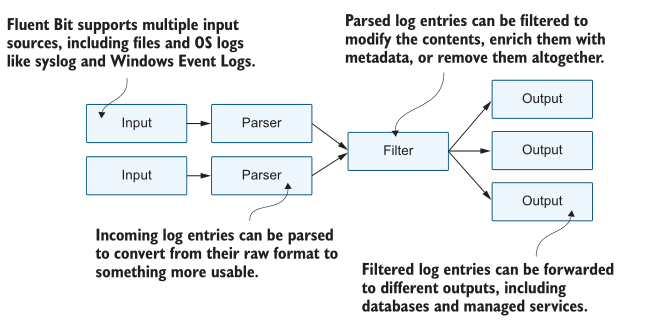
我们目前正在运行一个简单的配置,有三个阶段:输入阶段读取日志文件,解析器阶段分解JSON日志条目,输出阶段将每个日志作为单独的行写入Fluent Bit容器中的标准输出流。JSON解析器是所有容器日志的标准,并不是很有趣,因此我们将重点关注清单13.1中的输入和输出配置。
清单 13.1 fluentbit-config.yaml, 一个简单的 Fluent Bit 管道
[INPUT]
Name tail # 从文件末尾读取
Tag kube.* # 为标记使用前缀
Path /var/log/containers/timecheck*.log
Parser docker # 解析JSON容器日志
Refresh_Interval 10 # 设置检查文件列表的频率
[OUTPUT]
Name stdout # 写入标准输出
Format json_lines # 将每个日志格式化为一行
Match kube.* # 写入带有kube标记前缀的日志
Fluent Bit 使用标记来标识日志条目的来源。标签在输入阶段添加,可用于将日志路由到其他阶段。在此配置中,日志文件名用作标记,前缀为kube。匹配规则将所有带kube标记的条目路由到输出阶段,因此每个日志都被打印出来,但输入阶段只读取timcheck日志文件,因此这些是您看到的唯一日志条目。
您并不是真的想过滤输入文件——这只是一种快速入门的方法,不会让您被日志条目淹没。最好是读取所有输入,然后根据标记路由日志,这样就只存储感兴趣的条目。Fluent Bit内置了对Kubernetes的支持,它有一个过滤器,可以用元数据丰富日志条目,以识别创建它的Pod。过滤器还可以配置为每个包含命名空间和Pod名称的日志构建自定义标记;使用它,您可以更改管道,以便只有来自test命名空间的日志被写入标准输出。
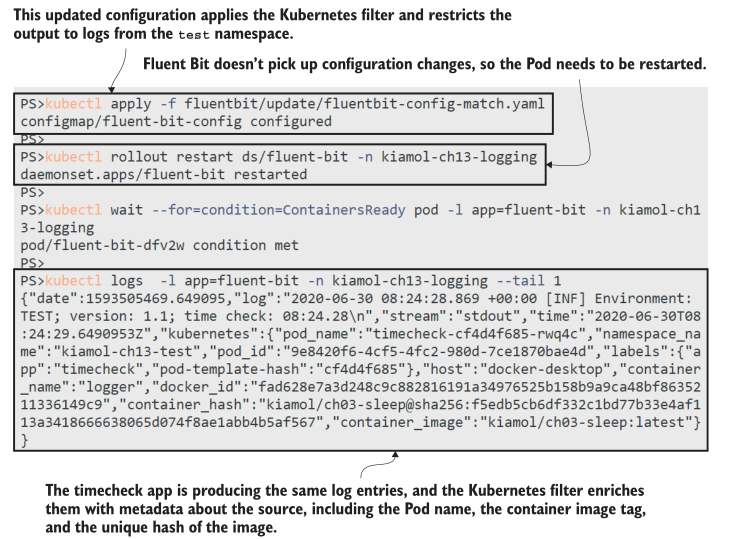
现在试试吧,更新Fluent Bit ConfigMap以使用Kubernetes过滤器,重新启动DaemonSet以应用配置更改,然后从timecheck应用程序中打印最新的日志以查看过滤器的功能。
# 更新数据管道配置文件:
kubectl apply -f fluentbit/update/fluentbit-config-match.yaml
# 重新启动DaemonSet,使一个新的Pod获得更改后的配置:
kubectl rollout restart ds/fluent-bit -n kiamol-ch13-logging
# 等待新的记录Pod:
kubectl wait --for=condition=ContainersReady pod -l app=fluent-bit -n kiamol-ch13-logging
# 打印最后一个日志条目:
kubectl logs -l app=fluent-bit -n kiamol-ch13-logging --tail 1
您可以从图13.7中的输出中看到,更多的数据来自Fluent bit—日志条目是相同的,但添加了日志源的详细信息。Kubernetes过滤器从API server 获取所有数据,这为您在分析日志以跟踪问题时提供了真正需要的额外上下文。查看容器的镜像散列可以让您完全确定地检查软件版本。
这个的Fluent Bit配置有点棘手。Kubernetes过滤器可以开箱即用地获取Pod的所有元数据,但是为路由构建自定义标记需要一些精细的正则表达式。这都在前面练习中部署的ConfigMap中的配置文件中,但我不打算重点讨论它,因为我真的不喜欢正则表达式。这也没有必要——设置是完全通用的,所以你可以将输入、过滤器和解析器配置插入到你自己的集群中,它将适用于你的应用程序,无需任何更改。
输出配置将有所不同,因为这是您配置目标的方式。在插入日志存储和搜索组件之前,我们将研究Fluent Bit的另一个特性——将日志条目路由到不同的输出。输入配置中的正则表达式为kube.namespace.container_name.pod_name格式的条目设置了一个自定义标记,可以在匹配中使用该标记根据命名空间或pod名称对日志进行不同的路由。清单13.2显示了具有多个目的地的更新输出配置。
清单 13.2 fluentbit-config-match-multiple.yaml, 路由到多个输出
[OUTPUT]
Name stdout # 标准的out插件将
Format json_lines # 只打印命名空间为
Match kube.kiamol-ch13-test.* # test的日志条目。
[OUTPUT]
Name counter # 计数器打印来自
Match kube.kiamol-ch13-dev.* # dev名称空间的日志计数。
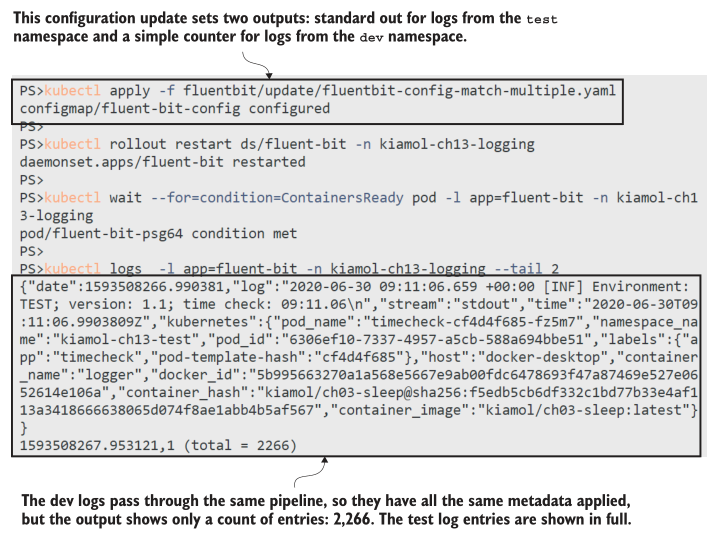
Fluent Bit支持许多输出插件,从普通TCP到Postgres和云服务,如Azure Log Analytics。到目前为止,我们使用的是标准输出流,它只是将日志条目中继到控制台。counter插件是一个简单的输出,它只打印已经收集了多少日志条目。部署新配置时,您将继续看到来自test命名空间的日志行,还将看到来自dev命名空间的日志条目计数。
现在试试吧,更新配置以使用多个输出,并从Fluent Bit Pod打印日志。
# 更新配置并重新启动Fluent Bit:
kubectl apply -f fluentbit/update/fluentbit-config-match-multiple.yaml
kubectl rollout restart ds/fluent-bit -n kiamol-ch13-logging
kubectl wait --for=condition=ContainersReady pod -l app=fluent-bit -n kiamol-ch13-logging
# 打印最后两行日志:
kubectl logs -l app=fluent-bit -n kiamol-ch13-logging --tail 2
本练习中的计数器并不是特别有用,但它可以向您展示管道早期部分的复杂可以使管道后面的路由更容易。图13.8显示了不同命名空间中的日志有不同的输出,可以在输出阶段中使用匹配规则进行配置。应该很清楚如何在Kubernetes编写的简单日志文件之上插入复杂的日志系统。Fluent Bit中的数据管道允许您丰富日志条目并将它们路由到不同的输出。如果你想使用的输出不被Fluent Bit支持,那么你可以切换到父项目Fluentd,它有一个更大的插件集(包括MongoDB和AWS S3)——管道阶段和配置非常相似。我们将使用Elasticsearch进行存储,它非常适合进行高性能搜索,并且易于与Fluent Bit集成。
13.3 向 Elasticsearch 发送日志
Elasticsearch 是一个生产级开源数据库。它将数据项作为文档存储在称为索引的集合中。这是一种与关系数据库非常不同的存储模型,因为它不支持索引中每个文档的固定模式——每个数据项可以有自己的一组字段。这很适合集中式日志记录,其中来自不同系统的日志项将具有不同的字段。Elasticsearch作为一个单独的组件运行,带有一个用于插入和查询数据的REST API。一个名为Kibana的配套产品提供了一个非常有用的Elasticsearch查询前端。您可以在与Fluent Bit相同的共享日志命名空间中运行Kubernetes中的两个组件。
现在试试吧,部署Elasticsearch和kibana—日志系统的存储和前端组件。
# 创建Elasticsearch部署,并等待Pod:
kubectl apply -f elasticsearch/
kubectl wait --for=condition=ContainersReady pod -l app=elasticsearch -n kiamol-ch13-logging
# 创建Kibana部署,并等待它启动:
kubectl apply -f kibana/
kubectl wait --for=condition=ContainersReady pod -l app=kibana -n kiamol-ch13-logging
# 获取Kibana的URL:
kubectl get svc kibana -o jsonpath='http://{.status.loadBalancer.ingress[0].*}:5601' -n kiamol-ch13-logging
Elasticsearch 和 Kibana 的基本部署分别使用一个Pod,如图13.9所示。日志很重要,因此您需要在生产环境中为高可用性建模。Kibana 是一个无状态组件,因此可以通过增加副本数量来提高可靠性。Elasticsearch 作为一个 StatefulSet 在多个使用持久存储的pod中工作得很好,或者你可以在云中使用托管Elasticsearch服务。当您运行Kibana时,您可以浏览到URL。我们将在下一个练习中使用它。

Fluent Bit有一个Elasticsearch输出插件,它使用Elasticsearch REST API为每个日志条目创建一个文档。该插件需要配置Elasticsearch服务器的域名,您可以选择指定应该在其中创建文档的索引。这允许您使用多个输出阶段从不同索引中的不同命名空间隔离日志条目。清单13.3将日志条目与test命名空间中的Pods和Kubernetes系统Pods分开。
清单 13.3 fluentbit-config-elasticsearch.yaml, 将日志存储在Elasticsearch索引中
[OUTPUT]
Name es # 来自test 命名空间的日志
Match kube.kiamol-ch13-test.* # 被路由到Elasticsearch,
Host elasticsearch # 并在“test”索引中作为文档创建。
Index test
[OUTPUT]
Name es # 系统日志创建在
Match kube.kube-system.* # 同一Elasticsearch服务器
Host elasticsearch # 的“sys”索引中。
如果有不匹配任何输出规则的日志项,它们将被丢弃。部署这个更新后的配置时,Kubernetes系统日志和test命名空间日志保存在Elasticsearch中,但不保存来自dev命名空间的日志。
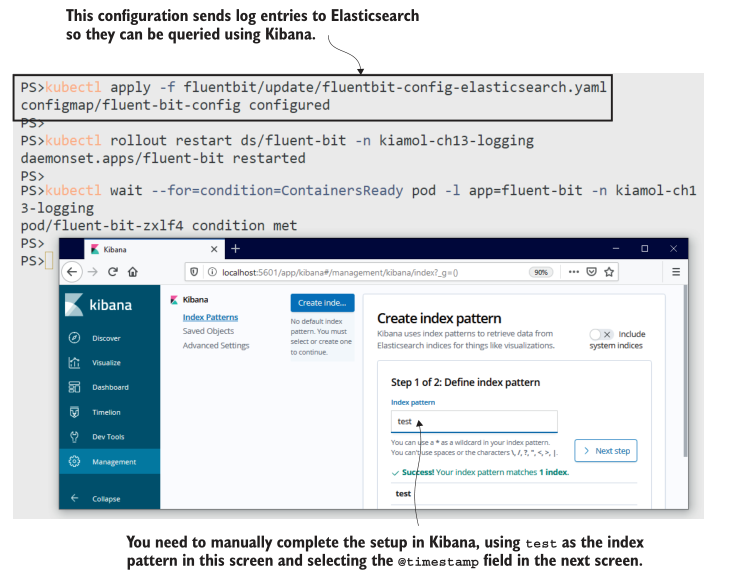
现在试试吧,更新Fluent Bit配置以将日志发送到Elasticsearch,然后连接到Kibana并在测试索引上设置搜索。
# 部署清单13.3中的更新配置
kubectl apply -f fluentbit/update/fluentbit-config-elasticsearch.yaml
# 更新Fluent Bit,并等待它重新启动
kubectl rollout restart ds/fluent-bit -n kiamol-ch13-logging
kubectl wait --for=condition=ContainersReady pod -l app=fluent-bit -n kiamol-ch13-logging
# 现在浏览到Kibana并设置搜索:
# - 单击左侧导航面板上的“发现”
# - 创建一个新的索引模式
# - 输入“test”作为索引模式
# - 在下一步中,选择@timestamp作为时间筛选字段
# - 单击创建索引模式
# - 再次单击左侧导航面板上的Discover查看日志
这个过程包含一些手动步骤,因为Kibana不是一个可以自动化的好产品。图13.10中的输出显示了正在创建的索引模式。当您完成该练习时,您将拥有一个强大、快速且易于使用的搜索引擎,用于测试命名空间中的所有容器日志。Kibana中的Discover选项卡显示了随时间存储的文档的速率(即日志处理的速率),您可以向下钻取每个文档以查看日志详细信息。
Elasticsearch 和 Kibana 都是成熟的技术,但如果你不熟悉它们,现在是了解Kibana UI的好时机。您将在 Discover 页面的左侧看到一个字段列表,您可以使用它来过滤日志。这些字段包含所有Kubernetes元数据,因此您可以根据Pod名称、主机节点、容器镜像等进行过滤。您可以构建显示按应用程序划分的日志的标题统计信息的仪表板,这对于显示错误日志的突然激增非常有用。您还可以在所有文档中搜索特定的值,当用户从错误消息中提供ID时,这是查找应用程序日志的好方法。
我不会在Kibana上花太多时间,但是再做一个练习就会展示集中式日志记录系统是多么有用。我们将把一个新的应用程序部署到test命名空间中,它的日志将自动由Fluent Bit提取并流到Elasticsearch,而不需要对配置进行任何更改。当应用程序向用户显示错误时,我们可以很容易地在Kibana中追踪到它。
现在试试吧,部署我们以前使用过的随机数API(在第一次使用后崩溃的API),以及缓存响应并几乎修复问题的代理。尝试API,当您得到一个错误时,您可以在Kibana中搜索失败ID。
# 部署API和代理:
kubectl apply -f numbers/
# 等待应用程序启动:
kubectl wait --for=condition=ContainersReady pod -l app=numbers-api -n kiamol-ch13-test
# 通过代理获取使用API的URL:
kubectl get svc numbers-api-proxy -o jsonpath='http://{.status.loadBalancer.ingress[0].*}:8080/rng' -n kiamol-ch13-test
# 浏览到API,等待30秒,然后刷新,直到出现错误
# browse到Kibana,并在搜索栏中输入这个查询:
# kubernetes.labels.app:numbers-api AND log:<failure-ID-from-the-API>
我在图13.11中的输出很小,但您可以看到发生了什么:我从API获得了一个失败ID,并将其粘贴到Kibana的搜索栏中,该搜索栏返回一个匹配项。日志条目中包含了我需要调查Pod所需的所有信息。Kibana还有一个有用的选项,可以在匹配前后显示文档,我可以使用它来显示围绕失败日志的日志条目。
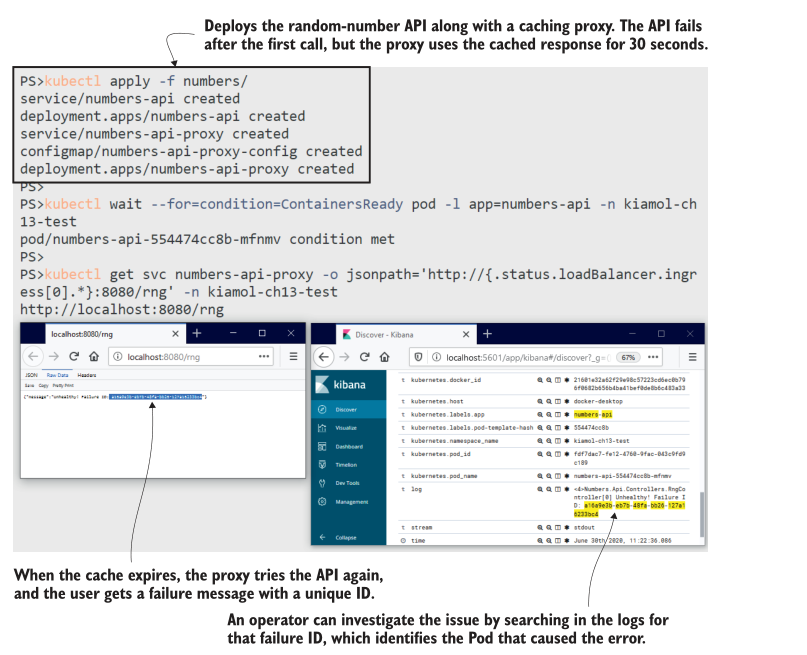
可搜索的集中式日志记录消除了故障排除中的许多摩擦,而且这些组件都是开源的,因此您可以在每个环境中运行相同的日志记录堆栈。在开发和测试环境中使用与在生产环境中使用的相同的诊断工具,可以帮助产品团队理解有用的日志级别,并提高系统日志的质量。高质量的日志记录很重要,但它在产品待办事项列表中很少排名靠前,所以在一些应用中,你会遇到一些用处不大的日志。Fluent Bit还有一些额外的特性可以提供帮助。
13.4 解析和过滤日志条目
理想的应用程序应该生成结构化的日志数据,其中包含条目的严重程度字段和写入输出的类的名称,以及事件类型的ID和事件的关键数据项。您可以在Fluent Bit管道中使用这些字段的值来过滤消息,这些字段将在Elasticsearch中显示,以便您可以构建更精确的查询。大多数系统不会产生这样的日志——它们只是发出文本——但如果文本使用已知的格式,那么Fluent Bit可以在它通过管道时将其解析为字段。
随机数API就是一个简单的例子。日志条目是如下所示的文本行:<6>Microsoft.Hosting.Lifetime[0] 现在监听http://[::]:80.尖括号内的第一部分是消息的优先级,然后是类的名称和方括号内的事件ID,然后是日志的实际内容。每个日志条目的格式都是相同的,因此Fluent Bit解析器可以将日志分解为单独的字段。为此必须使用正则表达式,清单13.4展示了我所做的最大努力,它只提取优先级字段,而将其他所有内容留在消息字段中。
清单 13.4 fluentbit-config-parser.yaml, 应用程序日志的自定义解析器
[PARSER]
Name dotnet-syslog # 解析器的名称
Format regex # 用正则表达式解析
Regex ^\<(?<priority>[0-9]+)\>*(?<message>.*)$ # 令人反感的
部署此配置时,Fluent Bit将有一个新的自定义解析器dotnet-syslog可供使用,但它不会将其应用于任何日志。管道需要知道哪些日志条目应该使用自定义解析器,而Fluent Bit允许您在Pods中使用注释进行设置。它们就像提示一样,告诉管道将命名解析器应用于源自此Pod的任何日志。清单13.5显示了随机数API pod的解析器注释——就是这么简单。
清单 13.5 api-with-parser.yaml, 带有自定义Fluent Bit解析器的Pod规范
# 这是部署规范中的Pod模板.
template:
metadata: # 标签用于选择器
labels: # 和操作;
app: numbers-api # 注释通常用于集成标志。
annotations:
fluentbit.io/parser: dotnet-syslog # 为Pod日志使用解析器
解析器可以比我的自定义解析器有效得多,Fluent Bit团队在他们的文档中有一些示例解析器,包括一个用于Nginx的解析器。我使用Nginx作为随机数API的代理,在下一个练习中,我们将为每个带有注释的组件添加解析器,并了解结构化日志如何在Kibana中实现更有针对性的搜索和过滤。
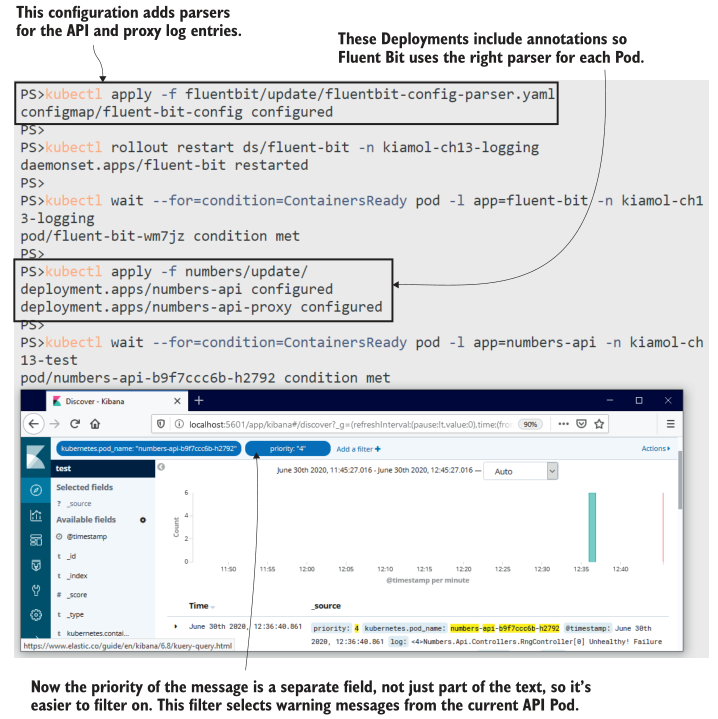
现在试试吧,更新Fluent Bit配置,为随机数应用程序和Nginx代理添加解析器,然后更新这些部署,添加指定解析器的注释。试试这款应用,在Kibana上查看日志。
# 更新管道配置:
kubectl apply -f fluentbit/update/fluentbit-config-parser.yaml
# 重启Fluent Bit:
kubectl rollout restart ds/fluent-bit -n kiamol-ch13-logging
kubectl wait --for=condition=ContainersReady pod -l app=fluent-bit -n kiamol-ch13-logging
# 更新应用部署,添加解析器注释:
kubectl apply -f numbers/update/
# 等待API准备就绪:
kubectl wait --for=condition=ContainersReady pod -l app=numbers-api -n kiamol-ch13-test
# 再次使用API,并浏览到Kibana查看日志
在图13.12中可以看到,Kibana可以对解析器中的提升字段进行筛选,而不需要构建自己的查询。在我的屏幕截图中,我过滤了来自一个Pod的日志,其优先级值为4(这是一个警告级别)。当你自己运行这个程序时,你会看到你还可以过滤API代理Pod。日志条目包括HTTP请求路径和响应代码字段,都是从Nginx文本日志中解析出来的。
使用 Fluent Bit的集中式日志记录系统的最后一个好处是:数据处理管道独立于应用程序,它是应用过滤的一个更好的地方。这个神话般的理想应用程序将能够动态地增加或减少日志级别,而不需要重新启动应用程序。然而,从第4章中你知道,许多应用程序需要重新启动Pod来获取最新的配置更改。当你在对一个实时问题进行故障排除时,这并不好,因为这意味着如果你需要提高日志级别,就需要重新启动受影响的应用程序。
Fluent Bit本身不支持实时配置重加载,但是重新启动日志采集器Pods比重新启动应用程序Pods具有更小的侵入性,并且Fluent Bit将从中断的地方开始,因此您不会错过任何日志条目。使用这种方法,您可以在应用程序中以更详细的级别记录日志,并在Fluent Bit管道中进行筛选。清单13.6显示了一个过滤器,它只在优先级字段的值为2、3或4时才包含来自随机数API的日志——它过滤掉了优先级较低的条目。
清单 13.6 fluentbit-config-grep.yaml, 根据字段值过滤日志
[FILTER]
Name grep # Grep是一个搜索过滤器。
Match kube.kiamol-ch13-test.api.numbers-api*
Regex priority [234] # 连我都能处理这个正则表达式
这里有更多的正则表达式争论,但是您可以看出为什么将文本日志条目分割为管道可以访问的字段很重要。grep过滤器可以通过计算字段上的正则表达式来包含或排除日志。当您部署这个更新的配置时,API可以愉快地在第6级写入日志条目,但是它们会被Fluent Bit删除,只有更重要的条目才会进入Elasticsearch。
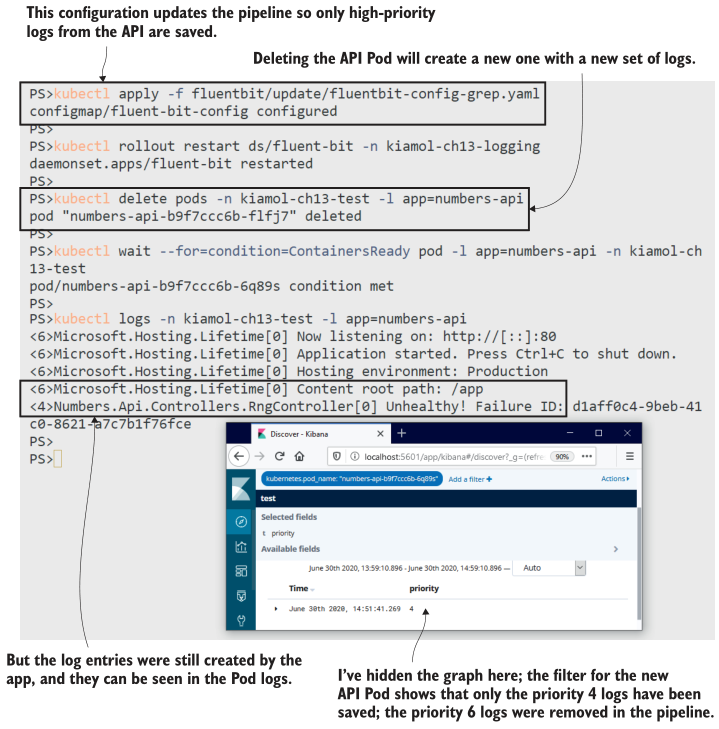
现在试试吧,部署更新后的配置,以便只保存来自随机数API的高优先级日志。删除API Pod,在Kibana中,你将看不到任何启动日志条目,但它们仍然存在于Pod日志中。
# 应用清单13.6中的grep筛选器:
kubectl apply -f fluentbit/update/fluentbit-config-grep.yaml
kubectl rollout restart ds/fluent-bit -n kiamol-ch13-logging
# 删除旧的API pod,这样我们就得到了一组新的日志:
kubectl delete pods -n kiamol-ch13-test -l app=numbers-api
kubectl wait --for=condition=ContainersReady pod -l app=numbers-api -n kiamol-ch13-test
# 使用API,并刷新,直到看到失败
# 从 pod里打印日志:
kubectl logs -n kiamol-ch13-test -l app=numbers-api
# 现在浏览到Kibana,并过滤显示API Pod日志
本练习向您展示了Fluent Bit如何有效地过滤日志,只将您关心的日志项转发到目标输出。它还显示较低级别的日志记录并没有消失——使用kubectl可以查看原始容器日志。 只是后续的日志处理阻止了他们使用Elasticsearch。在实际的故障排除场景中,您可以使用Kibana来识别导致问题的Pod,然后使用kubectl进行深入分析,如图13.13所示。
除了这些简单的管道,还有很多关于Fluent Bit的内容:您可以修改日志内容、限制传入日志的速率,甚至可以运行由日志条目触发的自定义脚本。但是我们已经介绍了您可能需要的所有主要特性,我们将通过比较收集-转发日志模型和其他选项来结束本文。
13.5 了解 Kubernetes 中的日志记录选项
Kubernetes 期望您的应用程序日志将来自容器的标准输出流。它收集并存储来自这些流的所有内容,这为我们在本章中介绍的日志模型提供了动力。这是一种通用而灵活的方法,我们使用的技术堆栈是可靠的和高性能的,但在整个过程中存在效率低下的问题。图13.14显示了将日志从容器中获取到可搜索存储器中的一些问题。
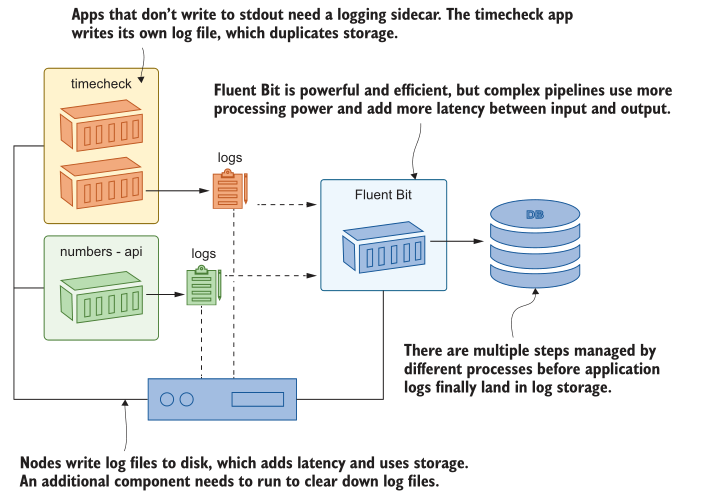
您可以使用更简单、移动部件更少的替代架构。您可以从应用程序代码直接将日志写入Elasticsearch,或者您可以在每个应用程序Pod中运行一个sidecar,从应用程序使用的任何日志sink中读取并将条目推入Elasticsearch。这将使您对存储的日志数据有更多的控制,而无需借助正则表达式来解析文本字符串。这样做将您绑定到Elasticsearch(或您使用的任何存储系统),但如果该系统提供了您所需要的一切,那么这可能不是一个大问题。
对于您在Kubernetes上运行的第一个应用程序来说,自定义日志框架可能很有吸引力,但是当您将更多的工作负载转移到集群时,它就会限制您。要求应用程序直接记录到Elasticsearch不适合写入操作系统日志的现有应用程序,而且您很快就会发现您的日志sidecar不够灵活,需要针对每个新应用程序进行调整。Fluentd/Fluent Bit模型的优势在于,它是一种标准方法,背后有一个社区;处理正则表达式比编写和维护自己的日志收集和转发代码要简单得多。
这就是应用程序日志的全部内容,因此我们可以清理集群,为实验室做好准备。
现在试试吧,删除本章的命名空间和剩余的Deployment。
kubectl delete ns -l kiamol=ch13
kubectl delete all -l kiamol=ch13
13.6 实验室
在本实验中,您将扮演一个操作员的角色,需要将一个新的应用程序部署到使用本章中的日志记录模型的集群中。您需要检查Fluent Bit配置,以找到您应该为应用程序使用的命名空间,然后部署我们之前在书中使用的简单版本网站。以下是这个实验室的部分:
- 首先在lab/logging文件夹中部署日志组件。
- 将应用程序从vweb文件夹部署到正确的命名空间,以便收集日志,并验证您可以在Kibana中看到日志。
- 您将看到日志是纯文本,因此下一步是更新部署以使用正确的解析器。应用程序运行在Nginx上,并且在Fluent Bit配置中已经为你设置了Nginx解析器。
- 当您在Kibana中确认新日志时,您将看到几个状态代码为304的日志,这告诉浏览器使用页面的缓存版本。这些日志并不有趣,因此最后的任务是更新Fluent Bit配置以过滤掉它们。
这是一个非常现实的任务,你需要在Kubernetes周围导航的所有基本技能来找到和更新所有的碎片。我的解决方案在GitHub上的常见地方,你可以检查:https://github.com/yyong-brs/learn-kubernetes/tree/master/kiamol/ch13/lab/README.md。