You have 2 free member-only stories left this month.
Building Domain Driven Microservices

Microservices — a definition
The term ‘micro’ in Microservices, though indicative of the size of a service, is not the only criteria that make an application a Microservice. When teams move to a microservices-based architecture, they aim to increase their agility — deploy features autonomously and frequently. It’s hard to pin down a single concise definition of this architectural style. I liked this short definition from Adrian Cockcroft — “service‑oriented architecture composed of loosely coupled elements that have bounded contexts.”
Though this defines a high-level design heuristic, Microservices architecture has some unique characteristics that differentiate it from the service-oriented architecture of the yesteryear. A few of those characteristics, below. These and a few more are well-documented — Martin Fowler’s article and Sam Newman’s Building Microservices, to name a few.
- Services have well-defined boundaries centered around business context, and not around arbitrary technical abstractions
- Hide implementation detail and expose functionality through intention-revealing interfaces
- Services don’t share their internal structures beyond their boundaries. For example, no sharing of databases.
- Services are resilient to failures.
- Teams own their functions independently and have the ability to release changes autonomously
- Teams embrace a culture of automation. For example, automated testing, continuous integration and continuous delivery
In short, we can summarize this architecture style as below:
Loosely coupled service-oriented architecture, where each service is enclosed within a well-defined bounded context, enabling rapid, frequent, and reliable delivery of applications.
Domain-driven design and Bounded contexts
The power of microservices comes from clearly defining their responsibility and demarcating the boundary between them. The purpose here is to build high cohesion within the boundary and low coupling outside of it. That is, things that tend to change together should belong together. As in many real-life problems, this is easier said than done — businesses evolve, and assumptions change. Hence the ability to refactor is another critical thing to consider when designing systems.
Domain-driven design (DDD) is a key, and in our opinion, a necessary tool when designing microservices, be it breaking a monolith or implementing a greenfield project. Domain-driven design, made famous by Eric Evans by his book , is a set of ideas, principles, and patterns that help design software systems based on the underlying model of the business domain. The developers and domain experts work together to create business models in a Ubiquitous common language. They then bind these models to systems where they make sense, establish collaboration protocols between these systems and the teams that work on these services. More importantly, they design the conceptual contours or boundaries between the systems.
Microservice design draws inspiration from these concepts as all of these principles help build modular systems that can change and evolve independently of one another.
Before we proceed further, let’s quickly go through some of the basic terminologies of DDD. A full overview of Domain-Driven Design is out of scope for this blog. We highly recommend Eric Evans’ book to anyone trying to build microservices
Domain: Represents what an organization does. In the below example, it would be Retail or eCommerce.
Subdomain: An organization or business unit within an organization. A domain is composed of multiple subdomains.
Ubiquitous language: This is the language used to express the models. In the example below, Item is a Model that belongs to the Ubiquitous language of each of these subdomains. Developers, Product Managers, domain experts, and business stakeholders agree on the same language and use it in their artifacts — Code, Product Documentation, and so on.
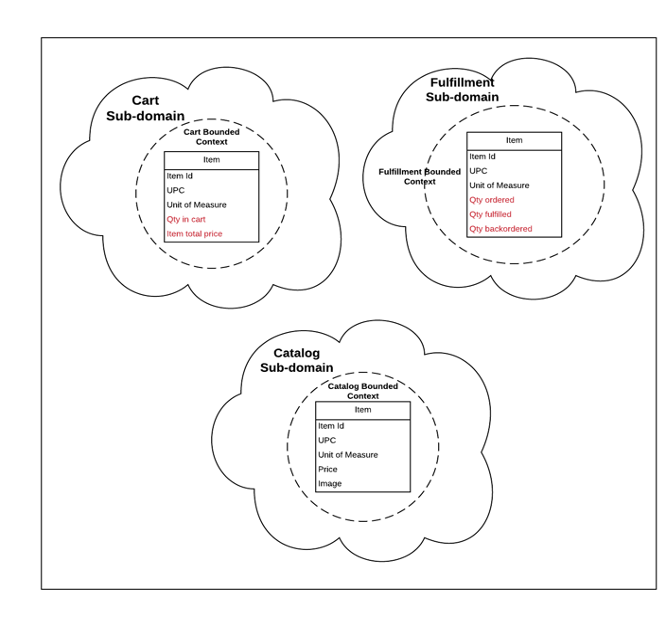
Bounded Contexts: Domain-driven design defines Bounded contexts as “The setting in which a word or a statement appears that determines its meaning.” In short, this means the boundary within which a model makes sense. In the above example, “Item” takes on a different meaning in each of those contexts. In the Catalog context, an Item means a sell-able product, whereas, in Cart context, it means the item that the customer has added to her cart. In Fulfillment context, it means a Warehouse Item that will be shipped to the customer. Each of these models is different, and each has a different meaning and possibly contains different attributes. By separating and isolating these models within their respective boundaries, we can express the models freely and without ambiguity.
Note: It’s essential to understand the distinction between Subdomains and Bounded contexts. A subdomain belongs in the problem space, that is, how your business sees the problem, whereas Bounded contexts belong in the solution space, that is, how we will implement the solution to the problem. Theoretically, each subdomain may have multiple bounded contexts, though we strive for one bounded context per subdomain.
How are Microservices related to Bounded contexts
Now, where do Microservices fit? Is it fair to say that each bounded context maps to a microservice? Yes and no. We will see why. There may be cases where the boundary or contour of your bounded context is quite large.

Consider the example above. The Pricing bounded context has three distinct models — Price, Priced items, and Discounts, each responsible for the price of a catalog item, computing the total price of a list of items, and applying discounts respectively. We could create a single system that encompasses all the above models, but it could become an unreasonably large application. Each of the data models, as mentioned earlier, have their invariants and business rules. Over time, if we are not careful, the system could become a Big ball of mud with obscured boundaries, overlapping responsibilities, and probably back to where we started — a monolith.
Another way to model this system is to separate, or group related models into separate microservices. In DDD, these models — Price, Priced Items, and Discounts — are called Aggregates. An aggregate is a self-contained model that composes related models. You could change the state of an aggregate only through a published interface, and the aggregate ensures consistency and that the invariants hold good.
Formally, An Aggregate is a cluster of associated objects treated as a unit for data changes. External references are restricted to one member of the AGGREGATE, designated as the root. A set of consistency rules applies within the AGGREGATE’S boundaries.

Again, it’s not necessary to model every aggregate as a distinct microservice. It turned out to be so for the services (aggregates) in Fig 3, but that’s not necessarily a rule. In some cases, it may make sense to host multiple aggregates in a single service, particularly when we don’t fully understand the business domain. An important thing to note is that consistency can be guaranteed only within a single aggregate, and the aggregates can only be modified through the published interface. Any violation of these bears the risk of turning into a big ball of mud.
Context maps — A way to carve out accurate microservice boundaries
Another essential toolkit in your arsenal is the concept of Context maps — again, from Domain Driven Design. A monolith is usually composed of disparate models, mostly tightly coupled — models perhaps know the intimate details of one another, changing one could cause side effects on another, and so on. As you break down the monolith, it’s vital to identify these models — aggregates in this case — and their relationships. Context maps help us do just that. They are used to identify and define relationships between various bounded contexts and aggregates. While bounded contexts define the boundary of a model — Price, Discounts, etc. in the example above, Context maps define the relationships between these models and between different contexts. After identifying these dependencies, we can determine the right collaboration model between the teams that will implement these services.
A full exploration of Context maps is beyond the scope of this blog, but we’ll illustrate it with an example. The below diagram represents the various applications that handle payments for an eCommerce order.
- The cart context takes care of online authorizations of an order; Order context processes post fulfillment payment processes like Settlements; Contact center handles any exceptions like retrying payments and changing the payment method used for the order
- For the sake of simplicity, let’s assume that all these contexts are implemented as separate services
- All these contexts encapsulate the same model.
- Note that these models are logically the same. That is, they all follow the same Ubiquitous domain language — payment methods, authorizations, and settlements. Just that they are a part of different contexts.
Another sign that the same model is spread around different contexts is that all of these integrate directly with a single payment gateway and do the same operations as one another

Redefining the service boundaries — Map the aggregates to the right contexts
There are a few problems that are very evident in the above design (Fig 4). Payments aggregate is part of multiple contexts. It’s impossible to enforce invariants and consistency across various services, not to mention the concurrency issues between these services. For example, what happens if the contact center changes the payment method associated with the order while the Orders service is trying to post settlement of a previously submitted payment method. Also, note that any change in the payment gateway would force changes to multiple services and potentially numerous teams, as different groups could own these contexts.
With a few adjustments and aligning the aggregates to the right contexts, we get a much better representation of these subdomains — Fig 5. There is a lot that has changed. Let’s review the changes:
- Payments aggregate has a new home — Payment service. This service also abstracts the Payment gateway from the other services that require payment services. As a single bounded context now owns an aggregate, the invariants are easy to manage; all transactions happen within the same service boundary helping to avoid any concurrency issues.
- Payments aggregate uses an Anti-corruption Layer (ACL) to isolate the core domain model from the payment gateway’s data model, which is usually a third-party provider and perhaps bound to change. We’ll dive deeper into the application design of such as service using Ports and Adapters pattern in a future post. The ACL layer usually contains the adapters that transform the data model of the payment gateway to the Payments aggregate data model.
- Cart service calls the Payments service through direct API calls as the cart service may have to complete the payment authorization while the customers are on the website
- Make a note of the interaction between Orders and Payment service. Orders service emits a domain event (more on this later in this blog). Payments service listens to this event and completes settlement of the order
- Contact center service may have many aggregates, but we are only interested in the Orders aggregate for this use case. This service emits an event when the payment method changes, and the Payments service reacts to it by reversing the credit card used prior and processing the new credit card.

Usually, a monolithic or a legacy application has many aggregates, often with overlapping boundaries. Creating a context map of these aggregates and their dependencies helps us understand the contours of any new microservices that we will wrest out of these monoliths. Remember, the success or failure of microservices architecture hinges upon low coupling between the aggregates and high cohesion within these aggregates.
It’s also important to note that bounded contexts are themselves suitable cohesive units. Even if a context has multiple aggregates, the entire context, along with its aggregates, can be composed into a single microservice. We find this heuristic particularly useful for domains that are a bit obscure — think about a new line of business the organization is venturing into. You may not have sufficient insight into the right boundaries of separation, and any premature decomposition of aggregates can lead to expensive refactoring. Imagine having to merge two databases into one, along with data migration, because we happened to find that two aggregates belong together. But ensure these aggregates are sufficiently isolated through interfaces so that they don’t know the intricate details of one another.
Event Storming — Another technique to identify service boundaries
Event Storming is another essential technique to identify aggregates (and hence microservices) in a system. It is a useful tool both for breaking monoliths and when designing a complex ecosystem of microservices. We have used this technique to break down one of our complex applications, and we intend to cover our experiences with Event Storming in a separate blog. For the scope of this blog, we want to give a quick high-level overview. Please watch Alberto Brandelloni’s video on the topic if you are interested in exploring further.
In a nutshell, Event Storming is a brainstorming exercise between the teams that work on an application — in our case, a monolith — to identify the various domain events and processes that happen within a system. The teams also identify the aggregates or models these events affect and any subsequent impacts thereof. As the teams do this exercise, they identify different overlapping concepts, ambiguous domain language, and conflicting business processes. They group related models, redefine aggregates and identify duplicate processes. As they progress with this exercise, the bounded contexts where these aggregates belong becomes clear. Event Storming workshops are useful if all the teams are in a single room — physical or virtual — and start to map the events, commands, and processes on a scrum-style whiteboard. At the end of this exercise, below are the usual outcomes:
- Redefined list of Aggregates. These potentially become new microservices
- Domain Events that need to flow between these microservices
- Commands which are direct invocations from other applications or users
We’ve shown a sample board at the end of an Event Storming workshop below. It’s a great collaborative exercise for the teams to agree on the right aggregates and bounded contexts. Besides being a great team-building exercise, the teams come out of this session with a shared understanding of the domain, ubiquitous language, and precise service boundaries.

Communication between microservices
To quickly recap, a monolith hosts multiple aggregates within a single process boundary. Hence managing consistency of aggregates within this boundary is possible. For example, if a Customer places an Order, we can decrement the Inventory of the items, send an email to the Customer — all within a single transaction. All operations would succeed, or all would fail. But, as we break the monolith and spread the aggregates into different contexts, we will have tens or even hundreds of microservices. The processes that hitherto existed within the single boundary of a monolith is now spread across multiple distributed systems. Achieving transactional integrity and consistency across all of these distributed systems is very hard, and it comes at a cost — the availability of the systems.
Microservices are distributed-systems as well. Hence, CAP theorem applies to them as well — “a distributed system can deliver only two of three desired characteristics: consistency, availability, and partition tolerance (the ‘C,’ ‘A’ and ‘P’ in CAP).” In real-world systems, partition tolerance is not negotiable — network is unreliable, virtual machines can go down, latency between regions can become worse, and so on.
So that leaves us with a choice of either Availability or Consistency. Now, we know that in any modern application, sacrificing availability is not a good idea either.

Design applications around eventual consistency
If you try to build transactions across several distributed systems, you’ll end up in the monolith land again. Only this time it will be the worst kind, a distributed monolith. If any of the systems become unavailable, the whole process becomes unavailable, often leading to frustrating customer experience, failed promises, and so on. Besides, changes to one service may usually entail changes to another service, leading to complex and costly deployments. Hence, we are better off designing applications tailoring our use cases to tolerate a little bit of inconsistency in favor of availability. For the example above, we can make all the processes asynchronous and hence eventually consistent. We can send emails asynchronously, independent of the other processes; If an item that’s promised is not available in the warehouse later, the item could be back-ordered, or we could stop taking orders for the item beyond a certain threshold.
Occasionally, you may encounter a scenario that might require strong ACID-style transactions across two aggregates in different process boundaries. That’s an excellent sign to revisit these aggregates and perhaps combine them into one. Event Storming and Context Maps will help identify these dependencies early on before we start breaking up these aggregates in different process boundaries. Merging two microservices into one is costly, and that’s something we should strive to avoid.
Favor event-driven architecture
Microservices can emit essential changes that happen to their aggregates. These are called Domain events, and any services that are interested in these changes can listen to these events and take respective action within their domains. This method avoids any behavioral coupling — one domain doesn’t prescribe what the other domains should do, and temporal coupling — the successful completion of a process doesn’t depend on all the systems to be available at the same time. This, of course, will mean that the systems will be eventually consistent.

In the example above, Orders service publishes an event — Order Cancelled. The other services that have subscribed to the event process their respective domain functions: Payment service refunds the money, Inventory service adjusts the inventory of the items, and so on. Few things to note to ensure the reliability and resiliency of this integration:
- Producers should ensure that they produce an event at least once. If there are failures in doing so, they should ensure there is a fall back mechanism present to re-trigger the events
- Consumers should ensure that they consume the events in an idempotent way. If the same event occurs again, there shouldn’t be any side effect at the consumer end. Events may also arrive out of sequence. Consumers can use Timestamp or version numbers fields to guarantee the uniqueness of the events.
It may not always be possible to use event-based integration due to the nature of some use cases. Please take a look at the integration between the Cart service and Payment service. It’s a synchronous integration, and hence has a few things we should watch out. It’s an example of behavioral coupling — Cart service perhaps calls a REST API from Payment service and instructs it to authorize the payment for an order, and temporal coupling — Payment service needs to be available for Cart service to accept an order. This kind of coupling reduces the autonomy of these contexts and maybe an undesirable dependency. There are a few ways to avoid this coupling, but with all these options, we will lose the ability to provide instant feedback to the customers.
- Convert the REST API to an event-based integration. But this option may not be available if the Payment Service exposes only a REST API
- Cart service accepts an order instantaneously, and there is a batch job which picks up the orders and calls the Payment service API
- Cart service produces a local event which then calls the Payment service API
A combination of the above with retries in case of failures and unavailability of the upstream dependency — Payment service — can result in a much more resilient design. For example, the synchronous integration between the Cart and the Payment services can be backed up by an event or batch-based retries in cases of failures. This approach has an added impact on the customer experience — the customers may have entered incorrect payment details, and we will not have them online when we process the payments offline. Or there may be an added cost to the business to reclaim failed payments. But in all likelihood, the benefits of the Cart service being resilient to the Payment service’s unavailability or faults outweigh the shortcomings. For example, we can notify the customers if we are not able to collect payments offline. In short, there are trade-offs between user experience, resiliency, and operating costs, and it’s wise to design systems, keeping these compromises in mind.
Avoid orchestration between services for consumer-specific data needs
One of the anti-patterns in any service-oriented architecture is that the services cater to the specific access patterns of consumers. Usually, this happens when the consumer teams work closely with the service teams. If the team was working on a monolithic application, they would often create a single API that crosses different aggregate boundaries, hence tightly coupling these aggregates. Let’s consider an example. Say the Order Details page in Web, and Mobile applications need to show the details of both an Order and the details of the refunds processed for the order on a single page. In a monolithic application, an Order GET API — assuming it’s REST API — queries Orders and Refunds together, consolidates both the aggregates and sends a composite response to the callers. It’s possible to do this without a lot of overhead as the aggregates belong to the same process boundary. Thus, consumers can get all the necessary data in a single call.
If Orders and Refunds are part of different contexts, the data is no longer present within a single microservice or aggregate boundary. One option to retain the same functionality for the consumers is by making Order service responsible for calling the Refunds service and create a composite response. This approach causes several concerns:
1. Order service now integrates with another service purely for supporting the consumers who need the Refund data along with Order data. Order service is less autonomous now as any changes in Refunds aggregate will lead to a change to the Order aggregate.
2. Order service has another integration and hence another failure point to take into account — if Refunds service is down, can Order Service still send partial data, and can the consumers fail gracefully?
3. If the consumers need a change to fetch more data from the Refunds aggregate, two teams are involved now to make this change
4. This pattern, if followed across the platform, can lead to an intricate web of dependencies between the various domain services, all because these services cater to the callers’ specific access patterns.
Backend for Frontends (BFFs)
An approach to mitigate this risk is to let the consumer teams manage the orchestration between the various domain services. After all, the callers know the access patterns better and can be in complete control of any changes to these patterns. This approach decouples the domain services from the presentation tier, letting them focus on the core business processes. But if the web and mobile apps begin to call different services directly instead of the one composite API from the monolith, it may cause performance overhead to these apps — multiple calls over lower bandwidth networks, processing and merging data from different APIs, and so on.
Instead, one could use another pattern called Backend for Front-ends. In this design pattern, a backend service created and managed by the consumers — in this case, the web and mobile teams — takes care of integration across multiple domain services purely to render the front-end experience to the customers. The web and mobile teams can now design the data contracts based on the use cases that they cater to. They can even use GraphQL instead of REST APIs to flexibly query and get back exactly what they need. It’s important to note that this service is owned and maintained by the consumer teams and not by the teams that own the domain services. The front-end teams can now optimize based on their needs — a mobile app can request a smaller payload, reduce the number of calls from the mobile app, and so on. Take a look at the revised view of the orchestration below. The BFF service now calls both Orders and Refunds domain services for its use case.

It’s also useful to build the BFF service early on, before breaking a plethora of services from the monolith. Otherwise, either the domain services will have to support the inter-domain orchestration, or the web and mobile apps will have to call multiple services directly from the front-end. Both of these options will lead to performance overhead, throw-away work, and lack of autonomy between the teams.
Conclusion
In this blog, we touched upon various concepts, strategies, and design heuristics to consider when we venture into the world of microservices, more specifically when we try to break a monolith into multiple domain-based microservices. Many of these are vast topics on their own, and I don’t think we’ve done enough justice to explain them in full detail, but we wanted to introduce some of the critical topics and our experience in adopting these. Further Reading (link) section has some references and some useful content for anyone who wishes to pursue this path.
Update: The next two blogs in the series are out. These two blogs discuss implementing the Cart microservice, with code examples, using Domain-Driven Design principles, and Ports and Adapters design patterns. The primary focus of these blogs is to demonstrate how these two principles/patterns help us build modular applications that are agile, testable, and refactorable — in short, be able to respond to the fast-paced environment we are all operating on.
Implementing Cart Microservice using Domain Driven Design and Ports and Adapters Pattern — Part 1
Implementing Cart Microservice using Domain Driven Design and Ports and Adapters Pattern — Part 2
Further Reading
1. Eric Evans’ Domain Driven Design
2. Vaughn Vernon’s Implementing Domain Driven Design
3. Martin Fowler’s article on Microservices